

Thèse présentée pour obtenir le grade universitaire de docteur en
Sciences du Langage
Céline HIDALGO
Résumé
La musique et la parole requièrent l’élaboration d’informations acoustiques qui changent dans le temps. De plus, la parole, et bien plus encore la musique, possèdent toutes deux un certain degré d’organisation temporelle, un certain degré de régularité dans le temps qui leur confère un caractère rythmique. Les stimuli de nature rythmique ont la particularité de pouvoir être anticipés par le cerveau et des études en linguistique et neurosciences ont montré que plus le cerveau est capable d’anticiper les évènements auditifs, meilleure est la qualité du traitement des stimuli. Les enfants sourds, bien que bénéficiant d’un input auditif de plus en plus précis grâce aux implants cochléaires ou aux prothèses conventionnelles et d’une prise en charge précoce, n’atteignent pas des niveaux de langage homogènes et souffrent toujours de difficultés de perception en milieux bruyants ou lors de conversations quotidiennes à plusieurs. La situation conversationnelle présente un contexte complexe, nécessitant l’activation de la voie audio-motrice pour anticiper et s’adapter aux variations de la parole de son interlocuteur notamment au niveau temporel. Dans ce travail de thèse, nous avons cherché à analyser, grâce à des mesures électrophysiologiques et comportementales, si un entrainement rythmique actif d’une durée de 30 minutes, stimulant la capacité d’anticipation de structures temporelles, pouvait avoir un effet sur les capacités de perception et d’accommodation temporelles de l’enfant sourd dans une tâche de dénomination en alternance avec un partenaire virtuel. Nous avons également testé les capacités rythmiques de ces enfants à différents niveaux de complexités acoustiques et structurales afin de mieux comprendre leurs déficits sous-jacents de perception temporelle de la parole. Les résultats montrent que les enfants sourds souffrent de difficultés structurer les événements acoustiques selon différent niveaux de hiérarchie (Hidalgo, Truy & Schön, en préparation) mais qu’un entrainement rythmique de 30 minutes versus une stimulation linguistique ou auditive, permet d’améliorer leurs compétences de perception et de production temporelles de la parole dans une situation d’interaction (Hidalgo, Falk & Schön, 2017; Hidalgo, Pesnot Lerousseau, Marquis, Roman, Nguyen, Schön, soumis)
I. Le rythme, une propriété importante pour la perception de la parole
1. Rythme de parole : un rythme musical ?
D’un point de vue physique, la musique comme le langage sont composés de sons complexes de différentes fréquences, intensités et durées qui se succèdent dans le temps. Autrement dit, lorsque nous écoutons de la musique ou la parole d’un interlocuteur, notre cerveau reçoit, en continu, un flux de stimulations acoustiques. Pour que ces deux activités fassent sens, notre cerveau doit en première instance parvenir à segmenter temporellement ce flux quasi-continu en unités qui seront pertinentes pour l’appréciation de la musique et la compréhension du langage. Sans le rythme, un auditeur ne pourrait pas créer du sens à partir des notes de musique qui se succèdent les unes après les autres, ni comprendre aisément le sens d’un discours.
Afin de structurer l’information auditive lors de l’écoute de la musique, le cerveau aura tendance à percevoir les durées des et surtout les intervalles temporels qui les séparent sons comme réguliers. Ainsi, les éléments temporels, i.e. notes ou intervalles, ne vont pas être appréhendés en fonction de leur durée absolue mais selon les rapports de régularité qu'ils entretiennent. Par exemple, les notes de musique ne vont pas être classées selon leur durée réelle en millisecondes (e.g. Do = 900 millisecondes et Si = 450 millisecondes) mais seront catégorisées selon les rapports simples de durées. En reprenant l’exemple ci-dessus, le Do sera considéré comme étant deux fois plus long que le Si. Le Do pourrait aussi durer un peu plus ou bien un peu moins et être encore perçu comme le double de la durée du Si. C’est grâce à ces rapports de durées des évènements et/ou entre les évènements que nous pouvons reconnaître des rythmes familiers lorsqu’ils sont joués à des tempi différents.
Dans la parole, la sensation de rythmicité est également présente mais cette rythmicité sera différemment perçue en fonction des langues. Des langues comme l’Anglais, le Russe ou l’Allemand ont été opposées, en termes de rythme, à des langues comme l’Espagnol ou le Français. Pike (1947) et Abercrombie (1967) ont ainsi défini deux groupes rythmiques de langues : des langues dont le rythme serait basé sur l’apparition régulière d’accents, dites stresstimed, et d’autres langues basées sur l’apparition périodique des syllabes dites syllabletimed. Une troisième classe de langues, nommée moratimed et marquée par des intervalles réguliers entre des consonnes géminées ou des voyelles longues (i.e. Honda contient deux syllabes mais trois mora : ho-n-da), a également été répertoriée ; cette classe contenait des langues comme le japonais (Pike, 1947; Abercrombie, 1967). Cependant, les études acoustico-phonétiques ne sont pas parvenues à démontrer une stricte régularité d’apparition autrement dit l‘isochronie des accent-syllabes-mora dans les différentes classes de langues comme pour la musique (Dauer, 1983). En se basant sur la notion de durées relatives, de nouvelles recherches ont tenté d’analyser le concept de régularité mais à partir des durées des voyelles et des consonnes (Ramus, Nespor, & Mehler, 1999) ainsi que la durée des intervalles qui sépare le début d’émission de chaque phonème dans différentes langues (Grabe & Low, 2002). Cette mesure, nommée Pairwise Variability Index, a permis de réaliser un nouveau classement des langues et bien que certaines langues semblent appartenir à un groupe commun, la catégorisation des langues en classes rythmiques distinctes selon ces critères, reste à appréhender avec précaution (Cummins, 2002). Cependant, la nature perceptuelle du rythme a poussé les chercheurs à mesurer la régularité non pas directement dans le signal acoustique mais plutôt dans le comportement des auditeurs, pour tenter de définir l’indice qui permettait de percevoir une rythmicité dans la parole. Ainsi, des études réalisées dans les années 70-80 (Marcus, 1981; Morton, Marcus, & Frankish, 1976) ont montré que lorsque des auditeurs doivent déterminer si des séquences de chiffres sont prononcées régulièrement ou pas ou produire des séquences de syllabes en rythme sur un métronome, ils n’utilisent pas le début du mot, i.e. l’onset, pour déterminer une régularité des intervalles dans la parole mais un point situé approximativement dans les 2/3 de la montée d’amplitude de la voyelle de chaque syllabe. C’est à partir des intervalles qui séparent ces points “perceptuels” nommés perceptualcenters ou pcenters, que les auditeurs parviendraient à percevoir et produire une régularité dans la parole, donc à ressentir ce qu’on peut assimiler à une pulsation dans la musique.
La pulsation ou beat en musique est une structure temporelle qui émerge perceptuellement de l’organisation régulière des durées entre les notes autrement dit du rythme de surface. En régularisant les rapports de durée entre les notes, le système perceptif génère une structure régulière de base, une période de référence qui est maintenue même en l’absence d’évènement dans le signal acoustique (figure 1.1).

Figure 1.1. Représentation de l’induction de la pulsation adaptée de Fitch (2013). Panel
A) Notation du rythme musical dans lequel sont insérées des silences. Panel B) Signal acoustique musical duquel ressort une succession d’évènement saillants (Panel C). Panel
D) depuis ces évènements saillants, notre système perceptif extrait une régularité d’apparition des évènements, la pulsation, qui pourra être perçue même en l’absence d’une matérialisation dans le signal acoustique (voir les silences dans la notation musicale) (Fitch, 2013).
Selon la Dynamic Attending Theory (DAT) (Large & Jones, 1999), l’émergence de la pulsation proviendrait de la capacité du système perceptif à distribuer l’énergie de l’attention sur des points perçus comme saillants dans le rythme musical grâce à un
mécanisme de couplage de nature oscillatoire entre le cerveau et le signal acoustique (Figure 1.2). Une fois l’oscillateur en phase avec le signal musical, celui-ci continuerait à osciller régulièrement ce qui maintiendrait l’orientation de l’attention dans le temps même en l’absence de signal.

Figure 1.2. Représentation de la synchronisation entre un oscillateur et un stimulus acoustique isochrone extraite de Jones (2016). Panel A) Stimulus isochrone. Panel B) Oscillateur dont l’amplitude de la phase détermine la concentration d’énergie attentionnelle. La phase de l’oscillateur va se recaler en fonction de l’attente du prochain évènement du stimulus. Panel C), lorsque l’oscillateur a suffisamment ajusté sa phase avec le stimulus, la concentration de l’énergie attentionnelle est moins dispersée (wide focus) et devient maximale sur les évènements du stimulus (narrow focus). L’oscillateur en oscillant sur ce nouveau mode synchronisé au stimulus, peut anticiper le prochain évènement en extrapolant son futur moment d’occurrence (Jones, 2016).
L’Attentional Bounce Hypothesis (ABH) (Pitt & Samuel, 1990) considère que le même type de mécanisme est actif lors de la perception de la parole: notre attention se porterait sur des évènements perceptivement saillants et réguliers du signal, en l’occurrence les p- centers, ce qui nous donnerait, selon le même type de mécanisme oscillatoire, la sensation d’une pulsation dans la parole mais plus spécifiquement sur les p-centers contenus dans les syllabes accentuées.
La sensation de rythmicité serait en effet également affectée par une autre structure temporelle de nature perceptive, la métrique. En musique, la métrique est un niveau de structuration du rythme, plus complexe que la perception de la pulsation. La perception de la métrique se situerait à un niveau plus profond de structuration temporelle du signal et consisterait à assembler les pulsations selon une alternance d’accents faibles et d’accents forts d’où émergeraient des patterns d’accents de différentes durées, intégrées les unes dans les autres de manière hiérarchique. La structuration hiérarchique de l’information acoustique en patterns accentuels ferait ressentir certaines pulsations, celles situées dans les hauts niveaux de la hiérarchie, comme plus saillantes que d’autres (figure 1.3).
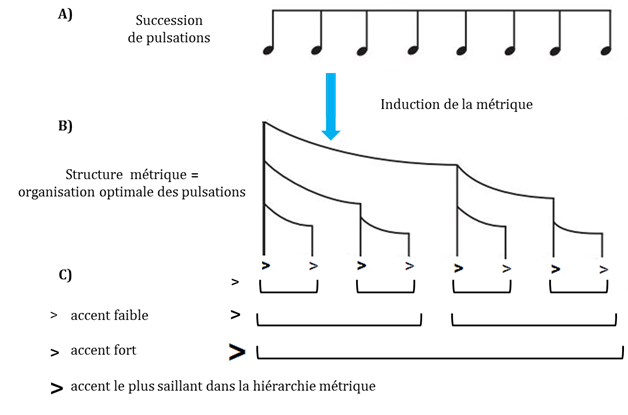
Figure 1.3. Représentation de l’émergence de la métrique. Panel A) les pulsations successives sont groupées en patterns d’accents fort/faible à différents niveaux (panel B). Panel C) ces patterns d’accents sont ensuite structurés selon différents niveaux de hiérarchie. L’auditeur perçoit ainsi une structuration optimale de l’input acoustique à différentes échelles temporelles.
Dans la parole, il est également possible de considérer une structure métrique qui émanerait de l’organisation de syllabes accentuées (notée X) versus non accentuées notées (x). On sait par exemple qu’il y a des langues donc l’accent des mots se porte généralement à gauche ce qui donne un pattern métrique de type iambique Xx et d’autres langues, qui ont plutôt un pattern métrique de type trochaïque xX avec l’accent à droite (Vaissière, 1991). Ce type de structure récurrente dans une langue permet de fixer un autre niveau d’organisation des p-centers. En outre, si l’on considère l’organisation des constituants prosodiques du français selon la classification de Jun et Fougeron (2002), on peut remarquer qu’ils sont également organisés de manière hiérarchique selon différents niveaux allant de la syllabe au syntagme intonatif avec, pour chacun des niveaux, un degré d’accentuation correspondant (voir figure 1.4) (Jun & Fougeron, 2002). Dans le domaine de la prosodie, l’accentuation en français est dite démarcative et a pour fonction de marquer la frontière droite de chaque constituant de l’énoncé afin de grouper les éléments en unités de sens. L’accent est réalisé par un allongement de la durée de la syllabe et cet allongement sera plus ou moins important en fonction du niveau hiérarchique du constituant dans l’énoncé ; la dernière syllabe du dernier constituant de l’énoncé dans la hiérarchie, le syntagme intonatif, sera par exemple celle qui recevra l’accent le plus important. Cette organisation permet de constituer une grille métrique des énoncés (voir figure 1.4).

Figure 1.4. Représentation de la structure rythmique ou grille métrique de l’énoncé adaptée de Di Cristo (2003).
Regroupement des syllabes en patterns de syllabes accentuées et non accentuées selon la hiérarchie des constituants prosodiques du français et émergence d’une grille métrique. Panel A) Structuration de l’énoncé selon les constituants prosodiques de Jun et Fougeron (2002). Panel B) Enoncé. Panel C) distribution des accents forts et faibles à travers les p-centers et organisation des patterns d’accents selon une hiérarchie de proéminence correspondant aux constituants prosodiques.
Nous aurions donc, en fonction des langues, une représentation perceptive différente de l’organisation temporelle des accents ou grille métrique qui accentuerait la perception d’une régularité dans la parole. Selon la DAT, ce processus perceptif complexe, similaire à celui réalisé lors de l’écoute de la musique, serait généré par le couplage de plusieurs oscillateurs avec les évènements saillants du stimulus acoustique à différentes échelles temporelles. Lorsque les différents oscillateurs se trouveraient en phase avec le beat, cela augmenterait la perception de l’accent le plus haut dans la hiérarchie autrement appelée le downbeat en musique que l’on pourrait assimiler à l’accent de syntagme intonatif dans la hiérarchie prosodique. La perception d’une métrique, en parole comme en musique pourrait être considérée comme une stratégie cognitive supplémentaire pour structurer le signal acoustique et générer des prédictions sur les évènements à venir.
Pour résumer, la perception du rythme serait commune au traitement de la musique et de la parole et elle comporterait au moins deux niveaux : un 1er niveau, le beat en musique et les syllabes (p-centers) dans la parole, et un 2ème niveau la métrique en musique et l’organisation des accents dans les mots et dans les différents constituants dans la parole. L’association de ces deux processus aurait pour effet d'augmenter notre attention sur différents points du signal et possiblement générer des prédictions quant à l’occurrence des évènements de musique et de parole à différents niveaux.
Dans le chapitre qui va suivre, nous allons voir que l’attention et les prédictions temporelles sont des processus cognitifs qui modulent la qualité de traitement de l’input sensoriel en particulier des stimuli auditifs dans des conditions d’écoute difficiles comme la perception dans le bruit ou les conversations à plusieurs.
2. L’entrainment rythmique : ou comment utiliser les propriétés de la temporalité de la parole et du fonctionnement neuronal pour améliorer la perception ?
Dans la partie précédente, nous avons vu que la rythmicité des signaux de musique et de parole, i.e. structure rythmique de surface, beat et métrique, permettait au cerveau de “régulariser” l’input auditif afin d’organiser sa perception ce qui aurait pour conséquence d’orienter l’attention sur les évènements pertinents du signal. Nous allons présenter dans cette nouvelle partie différentes études qui montrent que l’orientation de l‘attention sur des évènements qui apparaissent de manière régulière dans la musique comme dans la parole, améliore le traitement de l’information auditive. Nous décrirons ensuite comment les différentes théories tentent d’expliquer les effets de la régularité sur le traitement perceptif.
Dans le domaine musical, on sait que la présentation de notes de musique à des intervalles isochrones améliore la capacité à discriminer différentes hauteurs (Jones, Moynihan, Mackenzie, & Puente, 2002). Lorsque des auditeurs doivent juger de la similarité de la hauteur de deux notes disjointes, si ces notes sont espacées par d’autres notes apparaissant à des intervalles réguliers, les auditeurs obtiennent de meilleures performances comparées à une condition dans laquelle les notes seraient espacées par des intervalles irréguliers. On retrouve le même type d’effet de la régularité sur les temps de réaction et l’encodage des sons au niveau cortical et sous-cortical. Tillmann et Lebrun (2006) ont par exemple montré que les auditeurs diminuaient le temps de réaction lors de tâches de décision de similarité de hauteur des notes de musique lorsque les notes à analyser étaient insérées dans des séquences régulières plutôt qu’irrégulières (Tillmann & Lebrun-Guillaud, 2006). Tierney et Kraus (2013) ont également montré grâce à des mesures électrophysiologiques (potentiels évoquées corticaux et du tronc cérébral) qu’un son musical (onset) présenté en même temps qu'un extrait musical est mieux encodé au niveau cortical (i.e. onde P1 de plus grande amplitude) et sous-cortical (onde V de plus grande amplitude) lorsque ce son est présenté sur le beat plutôt que lorsqu'il est présenté en dehors du beat. A travers des tâches de discrimination phonémique ou de temps de réaction, des expériences ont également montré l’effet de la régularité de la parole sur le traitement perceptif (Tierney & Kraus, 2013). L’hypothèse de ces études était, comme en musique, que la régularité d’apparition des évènements à différents niveaux de hiérarchie dans le signal permettrait d’orienter, par anticipation, l’attention de l’auditeur sur les points à discriminer et augmenterait les ressources allouées à leur traitement. Quené et Port (2005) ont par exemple montré que lorsqu’on présente auditivement une liste de mots bisyllabiques, les auditeurs détectent plus rapidement un phonème-cible (e.g. le phonème /t/ dans /gato/) lorsque les p-centers des mots sont espacées par des intervalles réguliers comparé à des intervalles irréguliers (Quené & Port, 2005). Pitt & Samuel (1990) ont quant à eux testé les effets de la régularité générée non pas par les intervalles temporels entre les sons de parole mais par la régularité de la structure métrique des mots. Ils ont montré que lorsque des auditeurs entendent des listes de mots qui ont un pattern métrique régulier (e.g. avec un accent final systématique sur la dernière syllabe de mots bisyllabiques: patterns iambique), ils parviennent à détecter plus rapidement un phonème-cible comparé à une condition dans laquelle, les mots qui s’enchainent, comme dans une phrase, n’ont pas des patterns métriques identiques (Pitt & Samuel, 1990).
Une autre manière d’analyser les effets de la régularité sur la perception de la parole est la présentation, avant l’écoute d’un stimulus de parole, d’un amorçage de type rythmique reproduisant ou pas, la structure métrique de la parole. Cason et Schön (2012) ont par exemple fait entendre à des auditeurs des amorces rythmiques régulières suivies de non- mots bi et trisyllabiques. Ces amorces contenaient deux types de structures métriques marquées par des accents faibles et des accents forts qui correspondaient ou pas à la métrique des non-mots présentés. La tâche des participants était de décider, en pressant sur un boîtier de réponses, s'ils avaient perçu un phonème-cible dans les non-mots entendus. Le phonème à détecter était soit présenté sur la périodicité du beat, générée par l’amorce métrique (i.e. un accent fort apparaissait toutes les 700 ms), soit en dehors du beat et cela, dans les deux conditions d’amorce métrique (identique ou différente). Les résultats montrent que les auditeurs détectent plus rapidement les phonèmes-cible lorsque les phonèmes sont présentés sur le beat plutôt que off-beat et que ce résultat est encore amélioré lorsque la métrique de l’amorce correspond à la métrique du non-mot (effet d’interaction). En outre, des mesures électrophysiologiques (potentiels évoqués corticaux) montrent que les auditeurs ont bien détecté la violation de l'amorce métrique dans la condition où la métrique du mot n’était pas identique à l’amorce (N100) ainsi que la violation de la régularité de présentation du phonème sur le beat (P300) (Cason & Schön, 2012).
Pour résumer, dans la musique comme dans la parole la régularité de présentation des stimuli améliore les performances comportementales et électrophysiologiques dans des tâches perceptives. Lorsque le contexte est régulier, l’attention des sujets est facilement orientée sur les points saillants du signal car leur occurrence peut être anticipée. En outre, la perception de la métrique augmenterait cet effet en “attirant” par anticipation, les ressources attentionnelles sur les syllabes accentuées à différents niveaux.
Plusieurs théories ont tenté d’expliquer les processus neurocognitifs qui pourraient être à l’origine de cet effet de facilitation de la régularité sur le traitement perceptif.
Toutes ces théories partent du constat que l’activité du cerveau est de nature rythmique. Lorsque que l’on pratique un enregistrement de l’activité cérébrale (EEG), on peut en effet voir apparaître spontanément et en fonction des opérations cognitives réalisées durant la tâche, des oscillations rythmiques dans différentes bandes de fréquences. On recense essentiellement quatre bandes de fréquences oscillatoires : delta (1-3 Hz), theta (4- 7Hz), alpha (8-14Hz), gamma (40-80 Hz). Ces fréquences ont la particularité d’être organisées de manière hiérarchique : les plus lentes “contiennent” les plus rapides. On dit aussi que les fréquences rapides sont “nichées”, nested, dans les fréquences plus lentes (figure 1.6). Ces oscillations sont par ailleurs censées refléter les variations cycliques de l’excitabilité d’un ensemble de neurones. Autrement dit, lors du pic d’une oscillation plusieurs neurones se préparent à émettre en même temps, plusieurs potentiels d’action.
Une première théorie propose que selon que les évènements sensoriels arrivent au cortex au moment du pic ou du creux d’une oscillation, leur traitement, du fait du niveau d’excitabilité des neurones, va être respectivement amplifié ou atténué (Schroeder & Lakatos, 2009). Dans cette théorie, les oscillations corticales, par leurs fluctuations régulières, sont considérées comme un moyen pour le cerveau d’échantillonner le flux continu d’informations sensorielles, ou en d’autres termes, un filtre temporel. Plusieurs études dans le domaine visuel, sensorimoteur et auditif, semblent aller dans le sens de cette théorie. Il a par exemple été montré que si la phase des oscillations delta et theta était au niveau d’un pic d’oscillation juste avant l’arrivée d’une syllabe ambiguë, cela permettait aux auditeurs d'améliorer leurs capacités de catégorisation de cette syllabe, autrement dit de mieux la distinguer d’une autre syllabe (ten Oever & Sack, 2015).
Une deuxième théorie, la Dynamic Attending Theory (déjà évoquée dans la 1ère partie), postule que notre système auditif augmenterait le traitement du signal en synchronisant la phase de ses oscillations corticales avec la phase des stimuli rythmiques. La facilitation engendrée par la régularité serait le résultat du couplage automatique de deux oscillateurs, le stimulus rythmique et un oscillateur du cortex auditif dans le cas d’un stimulus simple comme un métronome ou de plusieurs oscillateurs dans le cas d’un stimulus complexe comme la musique ou la parole (voir figure 1.5). Cette théorie, considère que l’effet facilitateur de la rythmicité dans la musique est un processus de type bottomup, passif, dans lequel les oscillations du système sensoriel seraient entrainées par l’enveloppe temporelle du stimulus acoustique musical. Comme le signal musical, le signal de parole, contient deux types d’informations acoustiques : des informations de nature spectrale et d’autres de nature temporelle. La structure temporelle de la parole peut se décomposer en deux éléments : la structure fine, marquée par des fréquences extrêmement rapides (de 60 Hz à 10 KHz) qui permettent par exemple de différencier deux phonèmes opposés seulement par un trait comme le voisement ou de percevoir les transitions formantiques entre consonnes et voyelles. Le deuxième élément est l’enveloppe temporelle, marquée par des fluctuations lentes de l’amplitude du signal (de 2 à 50 Hz), qui encodent des informations de durée et d’intensité ou encore d’attaque et d’amortissement et qui permettent par exemple de distinguer deux consonnes qui s’opposent par leur mode articulatoire (constrictif versus occlusif). L’enveloppe temporelle permet aussi de percevoir le débit syllabique ou encore le rythme de la parole, marqué par la fréquence d’apparition des phonèmes, des syllabes et des accents (Rosen, 1992). Le rythme de la parole, serait ainsi reflété dans les fluctuations lentes de l’amplitude du signal acoustique qui se décomposent elles aussi en différentes bandes fréquentielles contenues les unes dans les autres comme pour les oscillations corticales (voir figure 1.6). On retrouve ainsi le rythme delta (approximativement entre 0.5 et 3 Hz) qui est la fréquence d’apparition des accents des différents constituants prosodiques, le rythme theta (compris entre 4 et 8 Hz) qui est la fréquence d’apparition des syllabes, et le rythme gamma (entre 30 et 80 Hz) qui est la fréquence d’apparition des phonèmes (Greenberg, 1999). Ainsi, l'enveloppe de la parole, par les informations temporelles qu’elle comporte, transmet un nombre d’informations important à différentes échelles temporelles qui vont être utilisées par le cerveau pour segmenter puis assembler les informations acoustiques de manière pertinente. On pourrait ainsi faire l’hypothèse que la régularité d’apparition des stimuli ou les amorces rythmiques délivrées avant le matériel verbal, auraient favorisé la synchronisation des oscillations neuronales du cortex auditif avec l’enveloppe temporelle de la musique et de la parole. Grâce à ce phénomène d’entrainment, la perception des informations acoustiques fines aurait pu être améliorée.
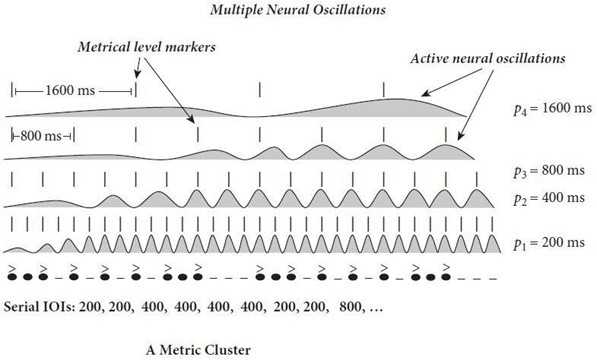
Figure 1.5. Représentation du couplage de phase de plusieurs oscillateurs avec les différents niveaux de régularité dans le stimulus acoustique extraite de Jones (2016). Plusieurs oscillateurs avec chacun différentes périodes (P1-P2-P3-P4), oscillent en même temps à différentes échelles temporelles correspondant à différents niveaux de régularités du stimulus. Lorsque plusieurs oscillateurs entrent en cohérence de phase, ils créent une relation entre les différents niveaux de la hiérarchie métrique : « metric clusters ». Une fois les clusters métriques établis, l’attention peut être plus flexible et se focaliser sur différents niveaux dans la hiérarchie et anticiper les évènements acoustiques à différents niveaux temporels.
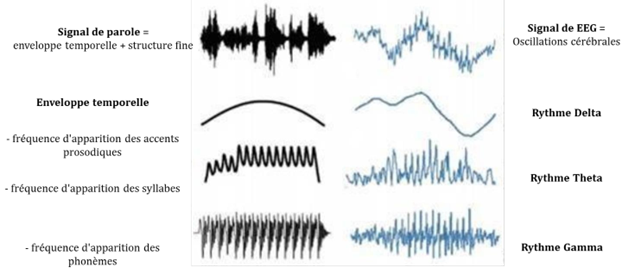
Figure 1.6. Représentation des fréquences dans l’enveloppe temporelle de la parole et dans l’activité cérébrale. A gauche, représentation du signal acoustique et d’une décomposition de l’enveloppe temporelle dans ses différentes bandes de fréquences. A droite, représentation des différentes bandes de fréquences contenues dans le signal EEG et leur caractère “nested” : les fréquences d’oscillation les plus lentes i.e. delta, contiennent les fréquences un peu plus rapides i.e. theta, qui contiennent les fréquences gamma qui sont les plus rapides.
Une troisième théorie la Predictive Coding theory propose que l’alignement de la phase (du pic) des oscillations neuronales avec la régularité des stimuli ne soit pas seulement le fait d’un entrainment passif de type bottomup mais aussi le résultat d’un mécanisme plus actif de prédictions temporelles. Selon cette théorie, la qualité de l’entrainment pourrait être modulée par des processus de type topdown. Une manière de mesurer les effets de ce processus topdown sur la qualité de la perception est de manipuler les attentes temporelles à plusieurs niveaux en l’absence d’une stricte régularité d’apparition (ou isochronie) des stimuli dans le signal acoustique. Dans une récente étude, Breska & Deouell (2016) ont par exemple manipulé la probabilité d’apparition d’un flash visuel : la cible visuelle pouvait soit apparaître sur le beat (onbeat), c’est à dire à un intervalle temporel identique aux intervalles séparant les flashs précédents, soit en dehors du beat (offbeat) (Breska & Deouell, 2016).
Cette dernière condition signifie que la cible avait une plus grande probabilité d’apparaître à un intervalle temporel différent de ceux précédemment présentés. Les résultats montrent que lorsque les cibles arrivent à demoments non attendus, les participants mettent plus de temps à répondre comparé à une condition dans laquelle les cibles arrivent de manière aléatoire. Ce qui est intéressant c’est que ce résultat est valable pour la condition on-beat comme offbeat. En effet, si le résultat obtenu dans la condition onbeat peut être imputable à l’entrainment du cortex visuel sur la régularité du stimulus, le résultat obtenu dans la condition offbeat serait lui, le résultat d’une synchronisation de phase due à la capacité du système à prédire l’occurrence des stimuli selon leurs probabilités d’apparition, et non en fonction de l’isochronie de leur occurrence. Ce type de prédictions, plus globales, faciliteraient également le traitement de l’information sensorielle en orientant les ressources attentionnelles sur des éléments pertinents pour la tâche. De nouveaux paradigmes sont actuellement en construction dans le domaine auditif afin de mesurer les effets de ces prédiction top-down dans le domaine auditif (c.f. Haegens & Zion Golumbic, 2018).
Pour résumer, le fonctionnement oscillatoire de notre cerveau nous permettrait de traiter les stimuli rythmiques avec plus de facilité en définissant des fenêtres attentionnelles de nature temporelles dans le flux de musique et de parole et en synchronisant la phase de ses oscillations sur les évènements prédictibles. L’orientation des ressources attentionnelles sur le stimulus acoustique pourrait être le fruit d’un mécanisme d’entrainment passif (bottomup) mais qui pourrait être modulé par un autre mécanisme plus stratégique, de prédictions temporelles (topdown) à un niveau global. Les oscillations neuronales étant “emboitées les unes dans les autres”, on peut penser que les prédictions plus globales, de type top-down, favoriseraient la synchronisation sur les fréquences lentes de la parole (informations sur la métrique prosodique) qui pourraient “contraindre” les oscillations de fréquences plus rapides à se mettre en phase avec les évènements de parole tels que les syllabes et les phonèmes; l’auditeur qui anticiperait la fin d’une unité prosodique pourrait en effet prédire le décours temporel des syllabes contenues dans cette unité prosodique. Ces deux processus neurocognitifs, bottomup et topdown, de nature temporelle optimiseraient le traitement de la parole aux différentes échelles temporelles et seraient spécifiquement actifs lors de la perception dans le bruit ou de conversations à plusieurs. Ces mécanismes seraient par ailleurs particulièrement développés lors de la pratique de la musique car cette activité cognitive de nature sensorimotrice, sollicite de manière accrue les compétences de traitement temporel à différents niveaux et nécessite une grande précision temporelle.
Dans la partie suivante, nous allons voir que la pratique de la musique améliore la perception de la parole, probablement grâce à une sollicitation accrue de la communication entre les structures auditives et motrices ce qui permettrait un traitement temporel de la parole plus précis de nature prédictive.
3. La pratique musicale : une activité rythmique qui améliore la perception de la parole
Les études mesurant les réponses électrophysiologiques à des stimuli de parole ont pu montrer que chez les musiciens, les neurones du tronc cérébral (colliculus inférieur), dévolus au traitement précoce de l'information auditive, réagissent plus rapidement et reproduisent de manière plus précise les caractéristiques acoustiques du stimulus (Kraus & Chandrasekaran, 2010; Wong, Skoe, Russo, Dees, & Kraus, 2007). Cela leur permet par exemple de mieux traiter et comprendre la parole dans le bruit (Parbery-Clark, Strait, & Kraus, 2011; Parbery-Clark, Skoe, Lam, & Kraus, 2009; Zendel, Tremblay, Belleville, & Peretz, 2015), de traiter avec plus de précision les différences entre les sons du langage (formants vocaliques pour les voyelles et transitions rapides pour les consonnes) (Parbery-Clark, Tierney, Strait, & Kraus, 2012) ou encore de mieux discriminer les changements de hauteur (Besson, Schön, Moreno, Santos, & Magne, 2007; Schön, Magne, & Besson, 2004) intervenant dans la structure de la prosodie et la valeur émotionnelle contenue dans un message verbal. Il est possible que le meilleur traitement de la parole chez les musiciens provienne de leur capacité à traiter l’organisation temporelle des sons avec plus de précision. Les musiciens discriminent des intervalles temporels plus petits comparé aux non musiciens ou des changements temporels plus subtils à l’intérieur de structures rythmiques (Rammsayer & Altenmüller, 2006). Les musiciens présentent également une réponse électrophysiologique (Negativité de Discordance : MMN) plus importante dans le cortex auditif gauche que les non musiciens lors de la détection de violations de la métrique en musique (Vuust et al., 2005), ce qui pourrait expliquer qu’ils parviennent à porter une attention plus importante aux structures métriques dans la musique (Kung, Tzeng, Hung, & Wu, 2011) comme dans la parole. Les musiciens parviennent en effet à mieux détecter une incongruité dans la structure métrique des mots terminant des phrases et leurs réponses électrophysiologiques (P200) à cette incongruité sont plus importantes que celles des non musiciens lorsque la détection de l’incongruité nécessite un traitement actif dans la tâche (i.e. la compréhension des mots) (Marie, Magne, & Besson, 2011). Les enfants musiciens sont également plus performants que les enfants non musiciens à détecter des violations syntaxiques en langage (Jentschke & Koelsch, 2009). Ces résultats semblent signifier que la pratique facilite la perception des structures temporelles contenues dans la musique et dans le langage ce qui influencerait leurs capacités de prédictions dans la parole. Les capacités de prédiction joueraient un rôle important dans l’extraction de régularités statistiques qui sont à la base de la segmentation de la parole. Les musiciens sembleraient lorsqu'il s'agit de segmenter un flux de parole dans une nouvelle langue (Francois & Schön, 2011). Une étude de Vuust et collaborateurs (2008) en magnétoencéphalographie a également montré qu’au plus les musiciens possèdent une expérience rythmique importante (i.e. les musiciens de jazz), au plus leur cortex auditif est sensible à des violations dans les structures rythmiques (MMNm) ; cet effet pourrait être expliqué par leurs capacités à générer des prédictions temporelles de haut niveau reflétées par l’amplitude de la P300m lors des violations métriques (Vuust, Ostergaard, Pallesen, Bailey, & Roepstorff, 2008). Ces prédictions de type predictive coding, implémentées dans les cortex frontal et pariétal, viendraient moduler de manière plus importante, comparé à des musiciens moins expérimentés en pratique rythmique ou des non musiciens, la réponse du cortex auditif à bas niveau. Il est intéressant de noter que la pratique du rythme mais aussi son écoute passive, sollicitent le système moteur (i.e. Aire Motrice Supplémentaire : AMS et cortex prémoteur) (J. L. Chen, Penhune, & Zatorre, 2008). Or, l’activité des structures motrices et les structures frontales semblent liées à la prédictibilité des stimuli. Ainsi, Bengtsson et collaborateurs (2009) ont montré dans une tâche qui n’impliquait aucune action motrice, que l’AMS était plus activée lors de l’écoute de structures de tons organisés selon une structure rythmique comparé à des séquences de tons distribués de façon aléatoire (Bengtsson et al., 2009). Les auteurs (Bengtsson et al., 2009) ont également montré que le cortex préfrontal était plus activé lors de l’écoute de structures métriques et non métriques impliquant une complexité rythmique et des capacités de prédiction plus importantes que le traitement d’une séquence de tons isochrones. Par ailleurs, comme le suggèrent des études montrant l’influence du système moteur dans des tâches de discrimination auditive de hauteur (Morillon, Schroeder, & Wyart, 2014) ou de phonèmes (Cason, Astésano, & Schön, 2015), l’implication du système moteur dans des tâches de perception améliore les performances des auditeurs. Il semblerait donc que la pratique de la musique et en particulier du rythme sollicitant la communication entre les structures motrices et frontales d’une part et les aires auditives d’autres part, soit à l’origine du meilleur traitement des stimuli acoustiques chez les musiciens. L’activation du système moteur lors de l’écoute des sons, augmenterait la synchronisation des oscillations du système auditif sur l’enveloppe des stimuli acoustiques de musique et de parole, ce qui faciliterait l’orientation de l’attention sur le signal acoustique et affinerait leur représentation.
II. L'interaction sociale : un contexte ou le rythme (de parole) est essentiel
Si la rythmicité contenue dans la parole, et de surcroit dans la musique, permet à l’auditeur d’activer des mécanismes neurocognitifs permettant d’améliorer le traitement du stimulus auditif, la situation d’interaction, qui est la situation la plus couramment rencontrée pour le traitement de la parole, va induire des modulations de ces processus (Dimitrios Kourtis, Sebanz, & Knoblich, 2010) et nécessiter des capacités d’anticipation et d’adaptation supplémentaires à celle d’une perception de la parole en situation isolée (Keller, Novembre, & Hove, 2014; Knoblich & Jordan, 2003). C’est pour cette raison qu’il apparaît important de remplacer les mécanismes de perception et de production de la parole dans un contexte interactionnel.
1. Le tour de parole, un contexte interactionnel qui nécessite prédiction temporelle et coordination
Aider un ami à transporter un canapé, jouer au tennis, au basket, danser, ou encore jouer de la musique avec d’autres musiciens requiert une coordination entre les individus pour que l’action puisse aboutir. Les patineurs artistiques doivent par exemple, lors d’une portée, coordonner précisément spatialement et temporellement leurs mouvements afin que cette figure soit réussie. Cependant, cette coordination inter-individuelle nécessite une constante adaptation aux comportements du partenaire qui peuvent, pour certains s’avérer imprévisibles. Par exemple, lors d’un match de handball, pour qu’une passe soit réussie, le receveur doit anticiper la trajectoire et la vitesse du ballon en fonction des mouvements et déplacements de son co-équipier. Mais il doit aussi tenir compte des différents adversaires qui peuvent faire obstacle au lanceur et provoquer probablement une déviation impromptue de son geste de lancer. Ce phénomène, nommé “coordination interpersonnelle”, revêt un caractère dynamique car les individus sont à la fois en constante adaptation mutuelle mais aussi en adaptation avec leur environnement. La coordination qui est présente dans la plupart des interactions sociales, est également présente dans les interactions verbales telles que la conversation qui nécessitent, de la part des interlocuteurs une adaptation ou accommodation temporelle fortement basée sur le rythme. En ce qui nous concerne, nous nous intéressons précisément aux mécanismes neurocognitifs permettant aux interlocuteurs de se coordonner mutuellement pour déterminer avec précision le moment de prise de tour de parole malgré toute la variabilité existante en termes de contenu et de longueur entre deux énoncés provenant de deux interlocuteurs différents.
a. La composante temporelle du tour de parole
Selon l’analyse conversationnelle, les interactions sociales sont régies par un certain nombre de processus et le tour de parole est un des processus majeurs mis en place par les interlocuteurs de manière récurrente dans les différents contextes conversationnels. Un des premiers modèles du tour de parole a été développé par Sacks et al., (1974) dans lequel les auteurs considèrent le tour de parole comme une unité d'interaction sociale construite et réinventée par les interlocuteurs tout au long de la conversation. Deux composantes déterminent un tour de parole : la 1ère composante est définie par les unités verbales c'est- à-dire les mots et phrases utilisés par chaque interlocuteur ; ces unités peuvent être de longueur très différente d'un tour à l'autre et sont appelées Turn Constructional Unit (TCU). La seconde composante est définie comme le moment le plus pertinent pour le changement de locuteur ; elle est nommée le Turn Relevant Place (TRP) (Sacks, Schegloff, & Jefferson, 1974). Dans ce modèle, plusieurs règles comportementales sont définies et doivent nécessairement être mutuellement respectées et comprises par les interlocuteurs afin que la prise de tour de parole puisse avoir lieu à un moment jugé opportun par l’un comme l’autre des deux interlocuteurs. Nous ne développerons pas les comportements non verbaux, ni les traitements lexico-syntaxiques qui sont des indices donnés et utilisés par les interlocuteurs pour déterminer la prise ou non du tour de parole. Cependant, l'analyse de l'organisation temporelle des tours de parole dans la conversation révèle que la plupart du temps, les interlocuteurs parviennent à se coordonner précisément afin que la parole de l'un ne chevauche pas celle de l'autre ni qu'il s'écoule un temps de silence trop important entre deux tours. Les auteurs (Sacks et al., 1974) résument ce principe par minimal gap et minimal overlap.
Selon Auer et collaborateurs (1999), l’organisation temporelle des tours de parole renfermerait un caractère rythmique dont la fonction serait de coordonner l’interaction verbale. Cette rythmicité des échanges permettrait de déterminer si un énoncé s'intègre ou non à un échange conversationnel. Une des stratégies adoptées par les locuteurs (anglophones) pour demeurer coordonnés temporellement lors d’une conversation, serait de modifier certaines caractéristiques de leurs syllabes afin de créer une continuité rythmique entre les tours. En se basant sur la perception des intervalles temporels qui séparent les syllabes accentuées de fin de tour, le locuteur qui se prépare à prendre la parole aura tendance à fixer la durée de la première syllabe accentuée de son tour de parole de manière à créer un intervalle isochrone entre la syllabe de fin tour de son interlocuteur et celle du début de son tour de parole (Auer, Couper-Kuhlen, & Müller, 1999). Une autre stratégie utilisée par les interlocuteurs pour conserver un degré de rythmicité dans l’échange serait la tendance à produire des mots comportant un nombre de syllabes identique d’un tour à l’autre ce qui crée selon les auteurs, une isométrie intra et inter-tour renforçant la perception rythmique de la conversation. Néanmoins, même si les portions de parole contenant une rythmicité forte (mesurées acoustiquement) sont rares, elles sont plus particulièrement présentes vers la fin des tours de parole (Szczepek Reed, 2010a). Le renforcement local (i.e. aux frontières des tours) des indices rythmiques dans la conversation semble indiquer que la conservation de la rythmicité de la parole joue bien un rôle fonctionnel dans la coordination des tours de parole. Dans une étude Szczepek Reed (2010b) a analysé au cours d’interviews, la rythmicité des échanges de paroles entre des locuteurs de deux communautés anglophones différentes. Ce type de conversation, composé d’échanges de question-réponse, a été spécifiquement choisi pour permettre aux auteurs de contrôler le temps de latence dû à la difficulté d’accès lexical. Les deux communautés participant à ces interviews différaient par la rythmicité de l’anglais parlé. En effet, le British English (BE) et le Singapour English (SE) présentent un rythme de parole différent : le rythme du BE qualifié de stresstimed, se reflèterait dans la régularité de la distribution de ses accents et le rythme du SE qualifié de syllabletimed, se reflèterait dans la durée isochrone des syllabes (Szczepek Reed, 2010b). Les résultats montrent que pour ces deux communautés, possédant un rythme de parole différent, la conservation de la rythmicité entre les tours est peu présente ce qui peut altérer la fluidité des échanges et modifier la portée pragmatique de la conversation (Beňuš, Gravano, & Hirschberg, 2011). En effet, si la rythmicité des échanges entre les locuteurs est mise à mal par des temps de latence trop importants ou des chevauchements trop nombreux entre les tours, soit l’interprétation globale des échanges de parole comme activité conversationnelle conjointe est rompue, soit, lorsque cette rupture de la rythmicité apparaît de manière sporadique, elle permet de guider les inférences conversationnelles. Par exemple, un silence d’une durée comprise entre 700 et 800 millisecondes entre deux tours de parole va laisser place à la génération d’une inférence de la part de locuteur. Ce dernier va interpréter le message à venir de son interlocuteur d’une manière différente, (probablement comme une forme de désaccord) de l’interprétation qu’il aurait faite si la réponse avait été articulée selon le délai “conventionnel“ compris entre 0 et 200 ms (Kendrick & Torreira, 2015).
b. Les prédictions temporelles dans le tour de parole
L’analyse temporelle de la prise de tour de parole lors d’un dialogue, montre que le moment auquel les interlocuteurs prennent la parole n’est pas aléatoire. Une étude de Stivers et collaborateurs (2009) a étudié des conversations spontanées dans 10 langues typologiquement éloignées les unes des autres et a pu mettre en évidence une véritable organisation temporelle des tours de parole malgré une variabilité importante dans la structure syntaxique des langues étudiées. Les auteurs ont prélevé les séquences de questions-réponses fermées (oui-non) et mesuré subjectivement, en demandant à un jury d’écoute, si les réponses semblaient retardées ou pas compte-tenu du rythme de la conversation. Ils ont également mesuré objectivement le temps de réponse en millisecondes par rapport à la fin de la question. Ce temps est positif quand il existe un silence entre la fin de la question et le début de la réponse et négatif quand il y a un chevauchement de parole. Lors de l’analyse de cet intervalle temporel dans les 10 langues différentes, on peut voir apparaître un pic unimodal s’étendant en moyenne de 0 à 200 ms (Stivers et al., 2009)(voir aussi l’avis nuancé sur la précision temporelle du tour de parole de Heldner & Edlund, 2010). Autrement dit, les locuteurs appartenant à différentes cultures et parlant différentes langues appréhendent une unité temporelle commune lors de leurs échanges verbaux ; les auteurs parlent d’une organisation universelle du tour de parole. La capacité des locuteurs à respecter ce temps “commun” entre les tours nécessite des capacités de prédiction temporelles. En effet, comme l’explique Levinson et Torreira (2015), la production d’un mot prend en moyenne 600 ms. Or, si les interlocuteurs parviennent à produire leur parole dans les 200 ms qui suivent la fin du tour de parole précèdent, c'est vraisemblablement qu’ils ont anticipé la fin de la parole du locuteur. La distribution du temps écoulé entre la fin du tour de parole du locuteur précédent et la prise de parole du locuteur suivant est nommée le Floor transfer offset (Levinson & Torreira, 2015) (voir figure 2.1). Lorsqu’on demande à des adultes de déterminer le moment le plus probable de la fin des plusieurs tours de parole issus de conversations spontanées, ils estiment ce moment (en pressant un boitier de réponse) en moyenne 200 ms avant la fin des tours. La manipulation des indices acoustiques a également permis aux auteurs de conclurent que cette anticipation était basée sur des indices lexico- syntaxiques (De Ruiter, Mitterer, & Enfield, 2006; Magyari & de Ruiter, 2012; voir Riest, Jorschick, & de Ruiter, 2015 pour une anticipation à partir des indices sémantiques).
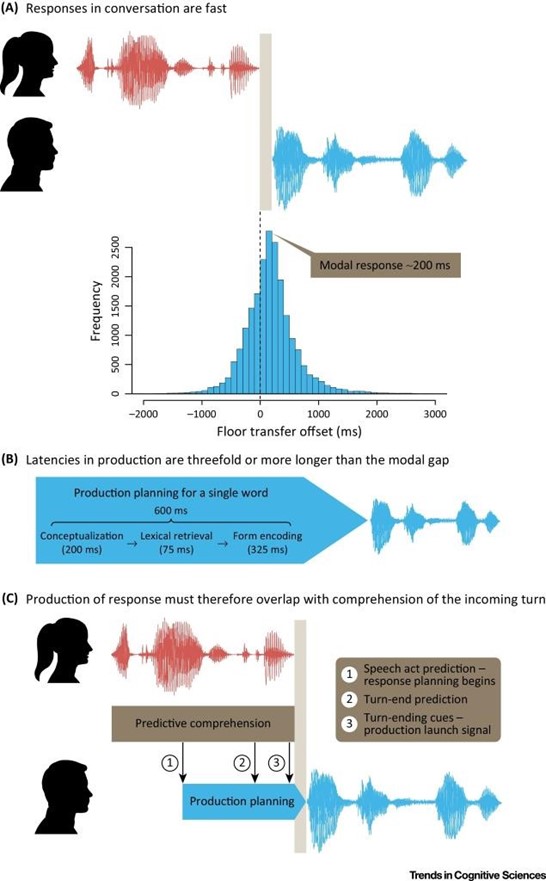
Figure 2.1. Représentation du décours temporel des tours de parole extraite de Levinson (2016). A) La parole du locuteur A (en rouge) se termine au point 0 du Floor Transfert Offset marqué par une ligne en pointillée. La durée des silences laissée par les interlocuteurs entre les tours est ainsi calculée depuis ce point 0 jusqu’au début de la parole du locuteur B (en bleu). La médiane des silences inter-tours se situe autour de 200 ms. B) Lorsqu’un locuteur produit un mot, les différentes étapes qui vont de la conceptualisation au début de la réalisation motrice prennent 600 ms. C) Pendant que locuteur A produit son message, le locuteur B génère constamment des prédictions en termes de contenu et de déroulement temporel du message. Ainsi en 1 le locuteur B prédit le type d’acte de parole (e.g. affirmation, question) que va produire le locuteur A en fonction du contenu précédent. En 2 le locuteur prédit le moment de la fin du tour de parole et en 3, en se basant sur les indices acoustiques de la fin du tour de parole, il détermine le moment où il va pouvoir commencer à parler. Pendant ces trois différentes étapes1-2-3, le locuteur B peut ainsi planifier sa réponse et la produire entre 0 et 200 ms en moyenne malgré le temps de planification-programmation que nécessite la production d’un mot (Levinson, 2016).
On peut se demander par quels mécanismes neurophysiologiques et processus cognitifs les locuteurs parviennent à anticiper la fin des tours de parole et à s’adapter aux variations temporelles présentes lors d’une conversation. Selon Keller, Novembre et Hove (2014), il est possible d’appréhender les compétences de coordination dans l’interaction verbale à la lumière des compétences requises lors de n’importe quelle action conjointe de nature rythmique car elles requièrent toutes un degré de précision de l’ordre de dizaines de milliseconde et des facultés d’accommodation temporelles. Ce type d’action conjointe, telle que la conversation ou la musique d’ensemble, engagerait des facteurs de réussite communs. Plusieurs facteurs entreraient en jeu lors de la réalisation d’une action conjointe tels que des capacités cognitives et sensori-motrices comme l’anticipation, l’adaptation et l’attention. Ces capacités seraient cependant affectées par d’autres facteurs tels que les connaissances communes des individus sur les règles du système, le degré de familiarité qu’ils entretiennent (e.g. le style de musique ou le degré de formalité de la conversation), le but de l’action et la stratégie utilisée pour réaliser l’action. Des facteurs sociaux tels que la personnalité affecteraient également la réussite de l’interaction (P. E. Keller et al., 2014) (voir figure 2.2).
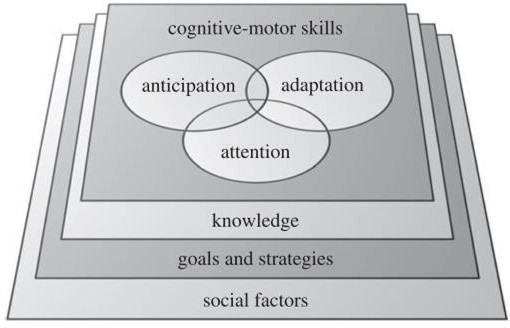
Figure 2.2. Représentation des facteurs qui affectent la coordination interpersonnelle pendant une action conjointe de type rythmique extraite de Keller et collaborateurs (2014).
2. Les mécanismes d’anticipation et d’adaptation dans l’interaction sociale
a. La convergence
L’interaction sociale engendre naturellement chez les individus de véritables comportements d’imitation réciproque. C’est ce que Chartrand & Bargh (1999) nomment l’effet caméléon. Cet effet est observable au niveau des postures, des mimiques faciales ou encore de certaines caractéristiques linguistiques. Chartrand & Bargh (1999) montrent par exemple que des inconnus qui se rencontrent dans le but de réaliser un travail commun vont automatiquement battre du pied ou se toucher le visage si leur partenaire de travail présente un de ces deux comportements. Ce type d‘imitation est nommé behavioral matching (Chartrand & Bargh, 1999).
Les interlocuteurs en situation d’interaction verbale modifient également leur manière de parler suite à l’influence exercée par leur partenaire conversationnel. Les interlocuteurs ont spontanément tendance à imiter réciproquement certaines caractéristiques de leur parole et selon la Théorie de l’Accommodation et de la Communication (Giles, Coupland, & Coupland, 1991) ces comportements imitatifs auraient pour but d’obtenir un maximum d’affiliation, de solidarité entre les locuteurs ainsi qu’une communication optimale i.e. une communication où les interlocuteurs parviennent à établir une inter -compréhension la plus fine possible (Fusaroli & Tylén, 2012).
Les interlocuteurs vont par exemple utiliser les mêmes structures linguistiques (Branigan, Pickering, & Cleland, 2000) et ce, même lorsqu’ils ne possèdent la même langue (Hartsuiker, Pickering, & Veltkamp, 2004), ils vont imiter des paramètres acoustico- phonétiques tels que l’intensité vocale (Natale, 1975), l'accent (Bourhis & Giles, 1977), une combinaison de caractères acoustiques (durée, fréquence fondamentale, les deux 1er formants, Pardo, 2006) mais également des paramètres avec une dimension temporelle tels que le débit de parole (Manson, Bryant, Gervais, & Kline, 2013; Street, 1984).
Ce type d’imitation, nommée convergence, est corrélée, comme le postulait la Théorie de l’Accommodation et de la Communication, au degré d’affiliation et de compréhension entre les interlocuteurs (Branigan et al., 2000; Garrod & Pickering, 2009; Street, 1984). Ainsi, en imitant réciproquement leurs caractéristiques linguistiques, donc en s’alignant sur des caractéristiques de bas niveau, les locuteurs “se rapprocheraient conceptuellement“ (voir la notion de situationals models de Zwaan & Radvansky, 1998), devenant ainsi plus prédictibles et diminueraient l’effort cognitif engagé dans la compréhension de la conversation (Garrod & Pickering, 2004; Pickering, 2006; Pickering & Garrod, 2007).
Levitan et collaborateurs (2015) ont également montré qu’au plus les interlocuteurs convergent sur des paramètres acoustiques à la fin du tour de parole, au plus ils parviennent à conserver des latences similaires entre les tours. Le phénomène de convergence sur la parole pourrait ainsi également servir aux locuteurs à se rapprocher “rythmiquement” dans la conversation afin de mieux se coordonner (Levitan, Beňuš, Gravano, & Hirschberg, 2015).
b. Le phénomène d’entrainment sur la parole
L’interaction semble être un contexte propice à la synchronisation temporelle entre les individus. Plusieurs études ont en effet montré que lorsque des individus se rencontrent, ils peuvent adopter naturellement des comportements rythmiques similaires et que ces comportements sont synchrones, c’est à dire que les deux individus effectuent des mouvements réguliers en même temps comme lorsque deux personnes marchent côte à côte et qu’elles synchronisent leurs enjambées. Une expérience de Richardson et collaborateurs (2007) a par exemple montré que des individus assis côte à côte sur un rocking-chair vont spontanément synchroniser leurs balancements tout comme des individus qui se voient mutuellement en train de faire osciller un pendule, vont naturellement les faire bouger de manière synchrone en phase (0°) ou en antiphase (180°) à la manière de deux oscillateurs qui se couplent. Ce phénomène d'imitation temporelle, commun aux deux études, s’établit alors qu'aucune instruction de coordination n’a été préalablement donnée aux participants (Richardson, Marsh, Isenhower, Goodman, & Schmidt, 2007). Cette forme d’imitation est appelée interactional synchrony. En se synchronisant mutuellement, les individus réduiraient leur variabilité intra-individuelle et deviendraient plus prédictibles l’un pour l’autre ; ce phénomène pourrait induire une augmentation de la précision des prédictions temporelles et une facilitation de la coordination inter-individuelle (Vesper, Van Der Wel, Knoblich, & Sebanz, 2011).
L’interactional synchrony, autrement dit la synchronisation spontanée en phase et en anti-phase entre des individus peut se retrouver également lors d’une interaction verbale. Himberg et collaborateurs (2015) ont montré par exemple montré que lorsque deux individus construisent une histoire en produisant des mots chacun leur tour à la manière d’une tâche de tapping en alternance, ils adaptent spontanément leur parole de manière à préserver des intervalles temporels de même durée que ceux réalisés par leur interlocuteur. En effet, même si la longueur des mots est très variable d’un tour à l’autre, les individus s’appuient sur le rythme de parole pour placer le début de chaque mot en fonction de l’intervalle temporel précédent. Cette synchronisation de la parole en anti-phase engendre la perception d’une rythmicité dans l’interaction verbale qui persiste même dans la situation où les interlocuteurs ne peuvent pas se voir (Himberg, Hirvenkari, Mandel, & Hari, 2015). Selon Wilson et Wilson (2005), ce serait la synchronisation mutuelle des oscillateurs internes des interlocuteurs sur le débit syllabique, autrement dit le couplage de deux oscillateurs, qui leur permettrait de prédire et préparer temporellement leur prise de tour de parole afin de rester synchronisés (Wilson & Wilson, 2005).
Cependant, comme le montrent d'autres études, il n’est pas nécessaire que la parole présente une structure périodique parfaite pour que des interlocuteurs parviennent à se synchroniser. Lire un texte ensemble est par exemple une activité très facile pour des interlocuteurs inconnus et inexpérimentés. Il semblerait en effet que même dans des conditions où le débit de parole n’est pas régulier, les individus parviennent à développer à partir du signal, des prédictions temporelles leur permettant de lire les mots en même temps à 40 ms près (Cummins, 2003). Ce résultat semble signifier que la parole, même peu régulière comme lors de la conversation spontanée, peut être un vecteur de synchronisation entre les individus et cette synchronisation inter-individuelle, bénéfique à l’interaction (Valdesolo, Ouyang, & Desteno, 2010), semble solliciter, comme la convergence, la voie sensori-motrice.
c. La voie sensori-motrice et les émulateurs internes
La synchronisation des mouvements des partenaires lors d’une interaction, comme le phénomène de convergence, semblent ressortir d’une synchronisation de type sensori- motrice : le système sensoriel perçoit un stimulus auditif (et/ou visuel) plus ou moins périodique, sur lequel il s’appuie pour envoyer un message au cortex moteur afin d’effectuer une action en fonction des caractéristiques de ce stimulus. Mais le système sensori-moteur fonctionne en boucle, c’est à dire avec des interactions bidirectionnelles entre cortex auditif et cortex moteur. Ainsi, si le système sensoriel interagit avec le système moteur afin qu'il se réajuste suite aux conséquences sensorielles des précédents mouvements, le cortex moteur renvoie également au système sensoriel des informations sur les possibles conséquences sensorielles des mouvements programmés (anticipation). Le système sensoriel peut alors renvoyer des informations au système moteur avant que le mouvement ne soit effectué pour qu’il atteigne la plus grande précision possible. Les conséquences réelles des mouvements, récupérées par le système sensoriel permettront, à force de réitérations, de réduire l’erreur de prédiction. Autrement dit, le système sensori-moteur utilise des mécanismes d’apprentissage par l’erreur qui permettent de réduire facilement la distance entre les mouvements effectués et le but à atteindre (voir figure 2.3 et Pickering & Clark (2014) pour la distinction entre Auxillary Forward Models et Integral Forward Models).

Figure 2.3. Modèle de prédiction de la perception et du réajustement de la réponse motrice dans l’interaction, adapté de Pickering et Clark (2014). Selon le modèle direct intégral (ou Integral Forward Model) de Pickering & Clark (2014), nous utiliserions le même module de prédiction - “modèle direct intégral” - pour anticiper les conséquences sensorielles de nos propres actions et celles de notre interlocuteur mais aussi pour ajuster nos programmes moteurs en fonction des comportements de l’autre. Ainsi, lors de la planification de la parole dans le tour de parole, nous anticiperions les conséquences temporelles de la parole de notre interlocuteur en utilisant les capacités de simulation de notre propre système moteur et nous pourrions ainsi planifier notre parole suffisamment à l’avance afin que le tour commence au moment optimal.
Notre modèle serait systématiquement mis à jour et affiné en fonction de la différence entre les conséquences sensorielles prédites par le “modèle direct intégral” et les conséquences sensorielles produites réellement.
Ce sont ces mêmes interactions entre les systèmes perceptifs et le système moteur qui sont à l’œuvre lors de la perception de la parole.
Depuis la découverte du système des neurones miroir (aire F5 du cortex prémoteur ventral) (Rizzolatti, Fadiga, Gallese, & Fogassi, 1996), plusieurs études ont montré que lorsque nous percevons de la parole, les régions motrices dévolues à la production de la parole telles que gyrus frontal inférieur gauche, le cortex prémoteur ventral et le cortex moteur primaire s’activent. En outre, on retrouve plus spécifiquement l’activation de régions somato-sensorielles liées aux mouvements de la bouche. Par exemple la partie du cortex moteur dévolue à l’activation des muscles de la langue s’active chez l’auditeur lorsque ce
dernier entend des mots impliquant la mobilisation de la langue d’un locuteur (Fadiga, Craighero, Buccino, & Rizzolatti, 2002). De même, stimuler à l’aide de la TMS les régions somato-sensorielles spécifiques à la réalisation articulatoire des certains sons de parole avant la perception de mots contenant ces sons, facilite le traitement en termes de temps de réaction et de pourcentage d’erreurs (D’Ausilio, 2009).
Un modèle de perception de la parole développé par Hickock et Poeppel (2007) met en évidence deux voies de traitement à savoir : une voie dorsale, avec des connexions bidirectionnelles qui relient les régions auditives temporales supérieures aux régions frontales en passant par la jonction temporo-pariétale ; cette voie aurait pour rôle de mettre en correspondance les sons et leurs représentations motrices. Et une voie ventrale qui assurerait la compréhension du message oral (représentations conceptuelle) via des liaisons entre les régions temporales supérieures et inférieures (Hickok & Poeppel, 2007) (voir figure 2.4).
Ainsi lorsque nous percevons de la parole, nous ne percevons pas seulement des éléments acoustico-phonétiques mais, grâce à l’activation des régions motrices, nous intégrons aussi les unités articulatoires correspondantes. En d’autres termes, comme le montre la Perception for Action Control Theory de Schwartz et collaborateurs (2008), nos représentations des unités de parole sont des représentations sensori-motrices (Schwartz, Basirat, Ménard, & Sato, 2012).
Ce modèle rejoint la théorie de la simulation (Wilson & Knoblich, 2005) ou de la résonance motrice qui postule que l’activation de notre système moteur, lors de l’observation de notre partenaire, nous permettrait lors d’une action conjointe, de générer des prédictions sur ses actions à venir et influencerait notre perception. Le système moteur semble en effet très impliqué dans nos interactions sociales, certains auteurs parlent même de “cognition motrice” (Jackson & Decety, 2004). Ce système comporterait un codage commun de l’information avec les systèmes sensoriels et serait le générateur de représentations internes nommées émulateurs. Ces représentations motrices de haut niveau étant partagées entre les individus, elles leur permettraient d'anticiper mutuellement leurs actions ainsi que leurs conséquences sensorielles. Cette théorie a été reprise pour la perception de parole (Gambi & Pickering, 2013) et expliquerait pourquoi l’imitation, qu’elle soit externe comme dans le cas de la convergence ou interne dans le cas d’une imitation motrice endogène des gestes du locuteur de la part l’auditeur, permettrait aux interlocuteurs de mieux se comprendre (Adank, Hagoort, & Bekkering, 2010; Adank, Rueschemeyer, & Bekkering, 2013) et de se coordonner avec précision lorsqu’ils entrent en interaction (Galantucci & Sebanz, 2009).
Scott, Mcgettigan et Eisner (2009) font en effet l'hypothèse d'une activation des cortex moteurs des auditeurs lorsqu’ils sont en train d’écouter un locuteur dans le cadre d’une situation d'interaction verbale. Ils postulent que l'activation de la voie dorsale (reliant les aires sensorielles auditives et les aires motrices en passant par la jonction pariétale) permet, lors du traitement de la parole, une activité motrice finement coordonnée qui assure un déroulement conversationnel fluide. Si la voie ventrale a pour rôle de décoder le message du locuteur d’un point de vue conceptuel, la voie dorsale serait dévolue dans les interactions verbales à contrôler les propriétés temporelles des échanges. Dans la voie dorsale, le rôle du système moteur - système impliqué dans la succession temporelle des actions - serait de suivre, i.e. d’imiter de manière endogène - le rythme et le débit de parole du locuteur et de permettre à l’auditeur d’anticiper la fin des tours de parole (Scott, Mcgettigan, & Eisner, 2009)(voir figure 2.4). Plus précisément, Hadley et collaborateurs (2015) ont montré que dans une tâche lors de laquelle deux pianistes doivent jouer les parties distinctes d’un morceau en alternance (un joue la main la gauche puis l’autre joue la main droite), la perturbation par TMS du cortex prémoteur dorsal et de l’aire motrice supplémentaire au moment de la transition entre les deux pianistes perturbait la fluidité temporelle dans la prise de tour des pianistes. Afin de mesurer l’importance de la simulation des gestes et de la conséquence de cette simulation endogène sur précision de la coordination temporelle dans la tâche, les morceaux ont été préalablement appris soit mains ensemble, autrement dit, pour certains morceaux, les pianistes connaissaient leur propre partie mais aussi celle de leur partenaire, soit les pianistes ont appris seulement la main les concernant. Les résultats montrent que plus la simulation motrice des gestes du partenaire est importante (mesurée pour les morceaux appris mains ensemble), meilleure est la précision de la coordination temporelle lors de la tâche (Hadley, Novembre, Keller, & Pickering, 2015). Novembre et collaborateurs (2014) ont également montré l’importance de la simulation motrice dans l’adaptation temporelle (coordination). Dans cette étude, des pianistes devaient jouer seulement la main droite de morceaux de musique dont la main gauche était enregistrée ; pour certains des morceaux, les musiciens se sont entrainés et les connaissaient par cœur mais pas pour d’autres. Les pianistes devaient ensuite s’adapter aux changements de tempo imposés par la main gauche enregistrée mais lorsque leur cortex moteur primaire a été perturbé (par d’un système de stimulation magnétique transcrânienne) au moment du changement de tempo, les pianistes ne parvenaient plus à s'adapter aux changements avec autant de précision pour les morceaux qu’ils connaissaient par cœur donc pour lesquels ils étaient capables de générer des simulations motrices. Par ailleurs, de manière intéressante, cette même étude a montré qu’au plus une personne est empathique, au plus l’effet de la perturbation de son système moteur lors de la tâche d’adaptation temporelle est important ce qui suggère que le niveau d’empathie pourrait influencer degré de résonance motrice d’un individu lorsqu’il se trouve en situation d’interaction et pourrait avoir un effet sur ses capacités de coordination (Novembre, Ticini, Schütz-Bosbach, & Keller, 2014). La résonance motrice, impliquant l’Aire Motrice Supplémentaire, le cortex prémoteur dorsal et le cortex moteur primaire semble ainsi indispensable à la génération de prédictions temporelles dans les interactions de type musical mais aussi dans d’autres interactions (Dimitrios Kourtis et al., 2010) comme le tour de parole .
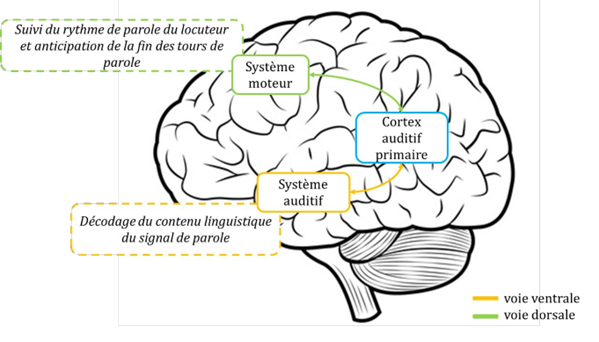
Figure 2.4. Représentation du rôle de la voie ventrale et de la voie dorsale dans le traitement de la parole, adaptée de Scott et collaborateurs (2009).
Les résultats de l’étude de Foti et collaborateurs (2016), convergent en effet vers le modèle de Scott et collaborateurs (2009) postulant l’importance de l‘activation endogène du système moteur dans la génération des prédictions temporelles nécessaires au tour de parole. En réalisant un enregistrement EEG simultanément à l’écoute de conversations téléphoniques contenant des paires de questions - réponses car pour ce type de paires, le moment à partir duquel la réponse sera produite est hautement prédictible, ces auteurs ont réussi à montrer que l’anticipation temporelle de la prise des tours de parole avec une durée du silence entre les tours comprise entre 200 et 700 ms (fourchette temporelle qui prédit un accord entre les interlocuteurs et donc une réponse positive immédiate) était reflétée par une réponse évoquée (stimulus-preceding negativity : SPN) générée par des régions postérieures (gyrus temporal postérieur - gyrus supramarginal – cortex prémoteur et le médial cortex préfrontal) correspondant à la voie dorsale alors que le traitement de la réponse affirmative à une question délivrée après une durée de silence supérieure à 700 ms donc engendrant une négation suite à un désaccord entre les interlocuteurs, était reflétée par le complexe P2/N2/P3 générée par des activations allant du gyrus temporal supérieur vers le médial cortex préfrontal mais n’impliquant pas le cortex moteur. Si l’apparition de ce complexe dans la condition de la réponse non prévisible signe une allocation spécifique de l’attention sur les réponses inattendues, l’élicitation de la SPN, dans la condition attendue suggère l’implication de prédictions temporelles guidées par le système moteur lors de la perception d’une conversation (Foti & Roberts, 2016).
Ainsi, l’imitation et la synchronisation comportementale et verbale avec un partenaire sont des stratégies que développent naturellement les individus lors d’une interaction probablement parce - qu'elles impliquent une activation du système sensori-moteur et en particulier le développement de de modèles internes générateurs de prédictions temporelles. La participation importante du cortex moteur dans ces prédictions est une des sources des capacités d’ajustement lors de changement temporels lors d’une interaction.
Un autre processus, complémentaire au phénomène d’entrainement (bottomup et topdown) sur un stimulus auditif et du couplage sensori-moteur, pourrait être à l’origine des prédictions temporelles développées lors de l’interaction. Le couplage de phase de l’activité neuronale de deux personnes en train d’interagir serait en effet un processus supplémentaire qui pourrait expliquer les capacités de synchronie interactionnelle développées au cours d’une interaction (voir figure 2.5).
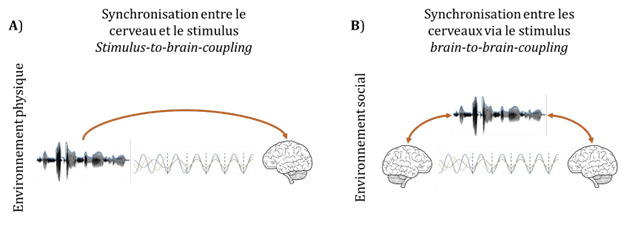
Figure 2.5. Représentation de la synchronisation stimulus-to-brain et brain-to-brain coupling adaptée de Hasson et collaborateurs (2012). A) Phénomène d’entrainement de l’activité oscillatoire sur un stimulus sensoriel extérieur (bottom-up) et de la modulation de l’entrainement par des processus attentionnels et de prédiction (top-down). B) Phénomène d’entrainement entre les activités oscillatoires de deux individus différents qui passe par le phénomène vu dans A) c’est à dire par la transmission entre les individus, d’un stimulus qui va leur permettre de synchroniser leurs activités cérébrales.
d. Synchronisation brain to brain
L’adaptation récente des protocoles expérimentaux utilisant l’imagerie, aux situations d'action conjointe, a permis de mieux comprendre le développement des prédictions temporelles durant les interactions en mesurant simultanément l’activité des cerveaux de deux individus.
Cette technique, appelée hyperscanning, a pu mettre en évidence que la synchronisation comportementale serait en quelque sorte “mimée” au niveau cérébral : lorsque deux individus parviennent à se synchroniser pendant une tâche motrice ou verbale, leurs cerveaux présentent également une activité synchronisée sur différentes bandes de fréquences.
Dumas, Nadel, Soussignan, Martinerie et Garnero (2010), ont réalisé des analyses EEG de cerveaux de couples de participants en train d’imiter réciproquement et librement les gestes de leur main. Les analyses révèlent une activation synchrone des régions centro- pariétales droites des deux individus dans les bandes de fréquences alpha-mu. L'activation synchrone de ces régions, particulièrement impliquées dans la perception temporelle, est retrouvée lorsque les participants commençaient et finissaient spontanément leurs mouvements de mains au même moment, autrement dit lorsqu’ils étaient dans des phases de synchronie interactionnelle (Dumas, Nadel, Soussignan, Martinerie, & Garnero, 2010).
Une autre étude (Kawasaki, Yamada, Ushiku, Miyauchi, & Yamaguchi, 2013) a utilisé un paradigme expérimental semblable à celui utilisé chez Himberg et collaborateurs (2015) en demandant à des sujets de prononcer les lettres de l’alphabet chacun leur tour tout en enregistrant leur activité cérébrale. Entre chaque série de lettres prononcées en alternance avec un partenaire humain, donc avec une parole plus ou moins irrégulière, chaque individu a effectué le même type de tâche avec une machine programmée pour délivrer chaque lettre à des intervalles temporels réguliers. Après analyse de la durée des productions de chaque participant et des intervalles qui séparent leurs productions (i.e. le rythme de parole et d’alternance) les résultats montrent que les rythmes de parole des participants sont mieux synchronisés dans la situation où les individus alternent avec un humain plutôt qu’avec une machine et que cette synchronisation entre les individus est plus importante après que les individus ont été stimulés par une rythmicité commune délivrée par la machine. Par ailleurs, les analyses EEG montrent une activité oscillatoire synchrone de leurs régions pariétales et temporales dans les bandes de fréquences thêta et alpha. En outre, l’augmentation de la synchronisation sur la parole a renforcé le degré de synchronisation de l’activité neuronale entre les individus (Kawasaki et al., 2013). En situation de conversation spontanée, on peut penser que le cortex auditif de l’auditeur serait entrainé sur les basses fréquences véhiculées dans l’enveloppe temporelle de la parole du locuteur ce qui lui permettrait d’anticiper le moment de la fin du tour de parole de ce dernier (Wilson & Wilson, 2005) et que l’activité synchrone dans des aires impliquées dans la perception temporelle et sur des bandes de fréquences beta dans les aires motrices (Novembre et al., 2017) permettrait aux interlocuteurs, par un effet prédictif topdown, de mieux se coordonner (Garrod & Pickering, 2015).
Ces résultats montrant que la synchronisation de l’activité neuronale entre les individus est liée à la synchronisation sur les rythmes de parole mais uniquement dans une situation d’interaction réelle, c’est à dire où les deux individus sont des humains (i.e. variables et adaptatifs) qui réussissent une tâche interactive (i.e. qui atteignent un but commun ou se comprennent), nous amènent à penser que la synchronisation neuronale interindividuelle joue un rôle prépondérant dans la coordination.
Par ailleurs, il semblerait que l’activité cérébrale d’un auditeur qui anticipe la parole d’un locuteur soit liée à une bonne compréhension du message sonore émis par le locuteur. Une étude (Stephens, Silbert, & Hasson, 2010) en Imagerie par Résonance Magnétique Fonctionnelle a été menée sur un individu en train de raconter une histoire a un autre individu. L’analyse de l’activité spatio-temporelle corticale des deux individus montre des patterns d’activité communs entre les deux individus (narrateur et auditeur) dans les aires auditives primaires lors du récit de l’histoire (i.e. lors de la vocalisation) et une activité anticipée (i.e. qui commence avant la perception de la parole) des aires préfrontales et du striatum chez l’auditeur. Cette synchronisation de l’activité neuronale entre les individus diminue lorsque les individus ne parlent pas la même langue (Stephens et al., 2010). Autrement dit lorsqu’un individu écoute un partenaire, les aires dévolues à la perception de la parole s’activent de la même manière chez les deux individus - ce résultat étant certainement dû à la synchronisation des cortex auditifs sur le stimulus de parole -mais surtout, l’écoute de la parole provoque chez l’auditeur une activité oscillatoire qui permettrait d’anticiper la structure temporelle du message oral.
Les locuteurs se serviraient finalement de deux mécanismes distincts mais complémentaires pour se synchroniser et s’adapter dans l’interaction (Galantucci & Sebanz, 2009) : un mécanisme basé sur un phénomène d’imitation sensori-motrice exogène et endogène de type bottomup et un mécanisme de synchronisation mutuelle des activités neuronales permettant la génération de prédictions temporelles de type topdown. Le modèle ADAM, que nous allons décrire dans la partie suivante, pourrait permettre d’expliquer comment les partenaires parviennent à réajuster leur comportement pour faire face à la variabilité de leur partenaire et ainsi maintenir une bonne coordination.
3. Un modèle d’explication de l’adaptation dans l’interaction : ADAM
Comme nous l’avons décrit précédemment, lorsque deux partenaires entrent en interaction, ils exercent une influence réciproque sur leurs mouvements, leur parole et sur la dynamique de leur activité neuronale. Cette influence qualifiée de véritable attraction et contrainte par Fusaroli, Raczaszek-Leonardi et Tylén (2014), est un moyen pour les partenaires de réduire la variabilité intra-individuelle afin de se rendre plus prédictibles pour une meilleure coordination lors de l’interaction (Vesper, van der Wel, Knoblich, & Sebanz, 2012; Vesper et al., 2011). Néanmoins, une coordination réussie est non seulement basée sur la précision temporelle de l’anticipation des actions futures de son partenaire mais aussi et surtout sur l'adaptation mutuelle durant l'action actuelle. L’anticipation temporelle est un comportement prédictif lors duquel un partenaire va anticiper le déroulement temporel des actions ou de la parole de l’autre partenaire alors que l’adaptation est comportement réactif lors duquel le partenaire va réajuster ses actions, sa parole, par un mécanisme de correction de l’erreur en fonction des variations temporelles de l’autre partenaire.
Les études menées sur la synchronisation sensori-motrice conjointe (i.e. tâche de tapping) ont pu montrer que l’accommodation temporelle à un partenaire se met en place très rapidement : les analyses de corrélation intertaps entre les partenaires montrent que ces derniers ont tendance à ajuster les intervalles temporels qui séparent deux de leurs taps pour s’approcher au mieux de ceux de leur partenaire dès les six premiers essais (corrélation positive à lag 0); et cet ajustement est bidirectionnel ce qui signifie qu’il n’y a pas un individu qui impose son tempo sans tenir compte de celui de l’autre (Konvalinka, Vuust, Roepstorff, & Frith, 2010). Cependant, lorsque le partenaire devient imprédictible (taps irréguliers) et qu’il ne s’adapte pas (i.e. ne tient pas compte des taps de l’autre individu), les capacités de synchronisation diminuent drastiquement.
Le modèle ADaptation and Anticipation Model (ADAM) de van der Steen et collaborateurs (2013) explique cette capacité à réajuster la programmation de ses propres mouvements en fonction de ceux d’un partenaire en réunissant deux approches: celle de la correction réactive de l’erreur gérée par la phase des oscillateurs internes et basée sur le pourcentage d’asynchronie entre le tap présent et le tap précédent, et celle de l’anticipation gérée par l’horloge interne ou encore appelée timekeeper qui se base sur la différence entre l’Inter-Onset-Interval (IOI) actuel et l’intervalle précédent conservé par le timekeeper (van der Steen & Keller, 2013).
Dans ce modèle, la correction de phase est un phénomène d’ajustement local et automatique (inconscient) dépendant de l’activation des cortex auditifs et somato-sensoriels alors que la correction de période (qui intervient lorsque le changement est trop important) est dépendante de l’activation de l’aire motrice supplémentaire et nécessite une attention consciente sur les changements de tempo. Selon que l’on interagit avec un partenaire coopératif ou non, on va plutôt utiliser un mécanisme fixe de correction de phase ou une alternance entre correction de phase et de période. Repp et collaborateurs (2010) montrent que dans une tâche de synchronisation sensori-motrice, les réseaux neuronaux associés à l’adaptation temporelle et impliquant à la fois des processus attentionnel et anticipatoires seraient pour la correction de phase, l’activation des régions cérébelleuses liées aux aires motrices et auditives. Pour la correction de période, on retrouve l’activation des régions des ganglions de la base, du cortex préfrontal, des régions préfrontales, frontales médiales et pariétales (Repp, 2010). Les musiciens, et plus particulièrement les musiciens d’ensembles, sollicitent sans cesse ce type de mécanismes et de manière très précise étant donné à la fois la régularité temporelle et les variations de tempo imposées par la musique ce qui pourrait améliorer leurs compétences de coordination dans l’interaction. C’est ce que nous allons voir dans la partie suivante.
4. Les effets de la pratique du rythme musical sur les prédictions et l’adaptation temporelles en situation d’interaction
La pratique de la musique sollicite de manière spécifique et répétitive les mécanismes et propriétés neurophysiologiques permettant le développement de prédictions temporelles nécessaires au processus d’adaptation et à l’optimisation de la perception de la parole en situation d’interaction.
En effet, comme le montrent Novembre et Keller (2014) dans un article de revue, les musiciens accomplissent de manière répétitive des tâches qui requièrent la mise en correspondance de stimuli auditifs et de mouvements, soit une activation importante du système auditif et du système moteur ce qui a pour effet d’augmenter l’intégration sensori- motrice des stimuli (Novembre & Keller, 2014 ; voir aussi Karpati, Giacosa, Foster, Penhune, & Hyde, 2016). Le couplage renforcé entre ces aires permet aux musiciens de générer de meilleures prédictions de l’erreur lorsqu’ils produisent des mouvements. La pratique de la musique génère en effet chez eux des modèles internes plus efficients sur les conséquences sensorielles de leurs gestes. Les tâches de synchronisation avec un métronome, qui demandent une coordination précise entre un stimulus auditif et un mouvement, ont montré que les musiciens sont plus consistants et plus précis que les non musiciens (Repp, 2010; Repp & Doggett, 2007). Mais les musiciens, possèdent également des représentations plus importantes de la structure des actions et peuvent alors anticiper avec plus de précision le but des actions des autres pour ensuite les intégrer à leurs propres actions (Novembre et Keller, 2014). Dans l’interaction, le couplage sensori-moteur est en effet un mécanisme essentiel qui permet à un individu d’intégrer les actions d'un autre individu (gestes, paroles) dans son propre répertoire moteur. Cette intégration permet de développer chez les deux individus en train d’interagir une représentation partagée de leurs actions et leur permet de parvenir à une compréhension sociale de de leurs actes (Knoblich & Sebanz, 2006). Autrement dit, une coordination inter-individuelle de bas niveau, basée sur des mécanismes sensori-moteurs, engendre une perception de plus haut niveau des actions du partenaire dans l’interaction. La coordination interindividuelle et la perception de haut niveau qui est d’ordre social, seraient améliorées par les mécanismes que sollicite la pratique de la musique (voir la notion de Dyadic Motor Plan développée par Sacheli, Arcangeli, & Paulesu, 2018).
En outre, lors des variations subites inhérentes à une situation d’interaction, les musiciens auraient également plus de facilités à s’adapter à des changements de tempo grâce à un meilleur entrainement de leurs oscillateurs internes sur les stimuli extérieurs mais aussi sur les rythmes endogènes de leurs partenaires. Loehr et Palmer (2011) ont demandé à des musiciens de reproduire des rythmes simultanément à l’écoute d’un métronome marquant la pulsation. Ce métronome a été manipulé afin de produire des variations de tempo au cours de la reproduction rythmique. Les résultats sont mieux décrits par un modèle de type oscillateur (qui se base donc sur des relations de phase) que par un modèle de type timekeeper (qui se base sur les durées absolues) (Loehr, Large, & Palmer, 2011). Ceci suggère, comme le laissent entendre les modèles sur le tour de parole (Garrod & Pickering, 2015; Wilson & Wilson, 2005) que la coordination en musique serait basée sur l’entrainement d’oscillateurs internes sur des stimuli rythmiques externes. En outre, des études portant sur la production d’une œuvre musicale à deux musiciens ont montré que les musiciens qui possédaient les rythmes endogènes les plus proches, mesurés à partir de plusieurs tâches de tempo spontané, sont également ceux qui sont parvenus à se coordonner avec la plus grande précision durant la performance musicale conjointe (Zamm, Wellman, & Palmer, 2016). Ce résultat suggère que le couplage des activités neuronales inter-individuelles pourrait être un facteur influençant la coordination dans les actions conjointes telles que la musique d’ensemble ou le tour de parole.
En résumé, la réalisation d’une action conjointe telle que la conversation nécessite, comme la pratique de la musique d’ensemble, des capacités d’anticipation et d’accommodation qui sont rendues possibles par différents mécanismes développés par les individus en situation d’interaction : imitation exogène (i.e. convergence), imitation endogène (i.e. activation du réseau sensori-moteur), capacité d’entrainement sur un stimulus extérieur et synchronisation des activités neuronales inter-individuelles. Les musiciens, grâce à leur pratique répétitive et exigeante, sollicitent de manière plus importante ces mécanismes ce qui leur permet de se coordonner avec plus de précision lors de tâches rythmiques mais surtout de s’adapter avec plus de facilité lors des variations temporelles qui ont lieu dans les situations d’interactions.
III. Le développement normal de la parole, un processus qui passe par le rythme de l'interaction
A la lumière des deux chapitres précédents, nous pouvons affirmer que pouvoir se synchroniser su l’enveloppe temporelle de la parole et structurer les évènements auditifs qui se déroulent dans le temps sont des processus essentiels pour la perception de la parole mais également pour la coordination avec un interlocuteur lors d’une conversation.
L’analyse des premiers échanges kinesthésiques et vocaux entre l'adulte et l’enfant, semblent montrer que ces processus se mettent en place très précocement et que ce “cadre” temporel est important pour l’enfant puisse développer la compréhension des unités de parole (Nazzi & Ramus, 2003) et devenir un partenaire conversationnel adapté.
1. Développement précoce de la perception et de la production de structures temporelles
La sensibilisation de l’être humain à la rythmicité commence dès l'exposition du fœtus à ses propres activités physiologiques primaires : battements cardiaques, succion, respiration, hoquet, déglutition mais également par la perception des rythmes physiologiques de sa mère. Grâce à la mesure des variations de son rythme cardiaque, il est en effet possible de mettre en évidence que dès 32 semaines d'âge conceptuel (AC), le fœtus réagit aux perturbations du rythme cardiaque de sa mère (Monk et al., 2000). La mesure des changements du rythme cardiaque du fœtus nous montre également que ce dernier est sensible à des variations rythmiques provenant de la perception de voix telles qu’elles lui parviennent par voie externe (Provasi, Anderson, & Barbu-Roth, 2014). La perception des indices rythmiques de nature verbale va continuer à s'affiner pour permettre au fœtus, entre 32 et 34 semaines d'AC, de distinguer sur la base de leurs caractéristiques prosodiques d'origine temporelle, la voix de sa mère de la voix d'une autre femme dont la fréquence fondamentale est par conséquent voisine de celle de sa mère (Kisilevsky et al., 2009).
Cette sensibilité précoce du fœtus aux caractéristiques temporelles du langage, va se refléter à la naissance. En effet, en enlevant les informations acoustiques correspondant aux informations phonétiques contenues dans le signal de parole, des études ont pu mettre en évidence que non seulement les nouveau-nés préfèrent écouter des patterns rythmiques accentuels qui proviennent de leur langue maternelle (Mehler et al., 1988) mais parviennent également, à quelques jours de vie seulement, à discriminer des langues à partir de leurs caractéristiques rythmiques (Nazzi, Bertoncini, & Mehler, 1998). Chez les bébés, l’intégration de patterns réguliers dans la parole est mise en évidence par la production de cris dont les contours mélodiques vont varier en fonction de la langue maternelle à laquelle ils appartiennent. Ainsi, les bébés allemands vont produire des cris avec des patterns mélodiques différents de ceux des bébés français. Alors que les premiers produisent un contour mélodique associant un ton montant puis un ton descendant, typique de celui le plus fréquemment retrouvé dans la prosodie de l’allemand chez l’adulte, les seconds produisent un contour mélodique associant un ton descendant puis un ton montant, retrouvé sur les frontières de constituants du français (excepté celui de frontière majeure qui est descendant) (Mampe, Friederici, Christophe, & Wermke, 2009). On sait également que les bébés de 9 mois préfèrent écouter des extraits de parole dont les pauses préservent un pattern métrique connu dans leur langue (dans cette étude pattern trochaïque) plutôt que des stimuli verbaux dont les pauses rompent ce pattern rythmique (Echols, Crowhurst, Childers, Becker, & Rader, 1997). Des bébés âgés de 8,5 mois préfèrent également écouter des extraits de parole avec des pauses qui correspondent à des frontières de phrases plutôt que des pauses à l’intérieur des phrases (Kemler Nelson, Hirsh-Pasek, Jusczyk, & Cassidy, 1989). La propension des bébés en période prélinguistique à grouper des unités de paroles en patterns, suggère que ce processus rythmique est sûrement déjà présent in utero.
Ces résultats vont de pair avec la capacité des enfants d'âge préverbal à percevoir des unités régulières i.e. des beats dans la parole. Dans les années 70, grâce à l'analyse de vidéos de nouveau-nés couplés à l'analyse d'oscillogrammes de la parole, des chercheurs ont pu mettre en évidence que lorsque des nouveau-nés en mouvement perçoivent la parole d’un adulte, ils produisent des changements dans leurs micro-mouvements corporels (i.e. mouvements des sourcils, des épaules, des pieds, des hanches) au moment de l'occurrence des phonèmes et des syllabes de l'adulte ; cet alignement des mouvements sur la parole est observable que l'adulte soit présent ou bien en réaction à de la parole enregistrée (Condon & Sander, 1974). On sait de plus que les enfants âgés de 11 à 24 semaines, peuvent discriminer si des clicks sont alignés avec les P-centers de la parole plutôt qu’avec l’onset des syllabes. Fowler a pu montrer dans une expérience complémentaire que le pattern de résultats observé était congruent avec le fait que les enfants perçoivent comme isochrones des syllabes alignées sur le p-center et anisochrones des syllabes alignées sur l’onset. En effet, le temps d’habituation plus long est observé pour des clicks alignés sur le p-center et de la parole isochrone à partir des P-centers. Dans l’expérience contrôle le temps d’habituation le plus long est observé pour des clicks alignés sur le p-center et de la parole objectivement isochrone, car composée d’une même syllabe (Fowler, Smith, & Tassinary, 1986). La synchronisation spontanée des mouvements sur la parole ainsi que la perception des P-centers comme beat rythmique dans la parole suggèrent que, comme le font les adultes, les enfants encore à un stade préverbal, sont capables d’extraire une pulsation régulière dans la parole en se basant sur des points d'ancrage perceptifs (cf. 1ère partie page 3).
La sensibilité précoce des nouveaux-nés à la temporalité présente dans la parole, va se manifester de manière encore plus prégnante lors de l’écoute d’autres types de stimuli réguliers et en particulier lors de l'écoute de la musique. Comme chez les adultes, le rythme musical, de par sa régularité intrinsèque et la répétition de cette régularité, va favoriser chez les bébés la synchronisation des mouvements sur le stimulus acoustique et l’émergence de structures temporelles. Ainsi, les enfants âgés entre 5 et 24 mois produisent plus de mouvements rythmiques lors de l’écoute de la musique ou d’un métronome comparé à l’écoute de la parole (Zentner & Eerola, 2010). Même si les capacités de synchronisation sont très dépendantes de la maturation du système sensori-moteur et que la précision de la synchronisation sur du matériel musical ne serait présente qu’à partir de 4 ans (McAuley, Jones, Holub, Johnston, & Miller, 2006), une récente étude (Fujii et al., 2014) a pu mettre en évidence, à l’aide de capteurs de mouvements, que les bébés, dès 3-4 mois, synchronisent leurs mouvements de jambes et leurs vocalisations lorsqu’ils entendent de la musique. Les bébés seraient donc capables, très précocement, d’extraire une pulsation dans la musique comme dans la parole, mais ils sont aussi capables de détecter et d’adapter leurs mouvements à des changements de tempo liés aux variations de la pulsation (Zentner & Eerola, 2010 ; Baruch & Drake, 1997). Des mesures électrophysiologiques confirment la capacité précoce des bébés à extraire la pulsation. Winkler et collaborateurs (2009) ont montré grâce à une mesure de négativité de discordance (MisMatch Negativity: MMN) que les nouveau-nés sont capables de détecter l’omission de la pulsation dans des séquences sonores musicales et que ces bébés, âgés de seulement quelques jours, réagissent plus particulièrement à l’omission du downbeat qui est la pulsation la plus importante dans la structure hiérarchique des structures rythmiques musicales. Ce dernier résultat suggère que les bébés ont été sensibles à l’organisation des pulsations selon une structure hiérarchique. Les bébés seraient en effet sensibles à différents niveaux de hiérarchie dans le stimulus acoustique. Ils préfèrent ainsi écouter des séquences de notes lorsque celles-ci sont organisées selon une structure métrique et particulièrement lorsque cette structure métrique est forte comparé à leur présentation en l’absence de structure ou d’une structure métrique plus faible (Bergeson & Trehub, 2006; Hannon & Trehub, 2005).
L’induction d’une pulsation dans la musique ainsi que la perception auditive précoce de patterns temporels musicaux sont des compétences temporelles présentes précocement chez l’enfant. Leur développement semble néanmoins facilité par la mise en mouvement. En effet, lorsque des enfants 7 mois entendent une suite de six pulsations non accentuées puis qu’ils sont habitués à être bercés, pendant deux minutes, toutes les 2 ou toutes les 3 pulsations, les enfants bercés toutes les 3 pulsations préfèreront ensuite écouter la séquence initiale de six pulsations, accentuée selon une métrique ternaire plutôt que binaire (Phillips- Silver & Trainor, 2005). Ces résultats vont dans le sens d’une récente étude (Cirelli, Spinelli, Nozaradan, & Trainor, 2016) montrant, à l’aide de mesures électrophysiologiques (Steady- State Evoked Potentials : SSEP), que les bébés âgés de 7 mois présentent, comme les adultes, des réponses neuronales qui reflètent la fréquence d’apparition de la pulsation et de la métrique lors de l’écoute de séquences isochrones de tons non accentués, donc ne marquant pas acoustiquement la métrique dans le stimulus (Cirelli et al., 2016; voir Nozaradan, Peretz, Missal, & Mouraux, 2011 pour l'adulte) (voir figure 3.1). Ces résultats suggèrent que les bébés comme les adultes développent précocement une cognition de type rythmique qui leur permet de percevoir des structures temporelles dans les stimuli acoustiques.

Figure 3.1. Représentation des réponses neuronales des enfants mimant la structure rythmique du stimulus au niveau du beat et du mètre extraite de Cirelli et collaborateurs (2016). A) Notation musicale du stimulus auditif composé d’une succession de tons et de silences espacés de manière isochrone Sont représentés en bleu, le beat (3Hz), en rouge la structure métrique binaire (1.5 Hz) et en vert la structure métrique ternaire (1Hz). B) Spectre de l’enveloppe temporelle C) Moyenne des réponses évoquées de tous les enfants dans laquelle on retrouve les fréquences du beat et des structures métriques binaire et ternaire.
Dans la partie suivante, nous allons voir que la sensibilité du bébé aux structures temporelles dans la parole et dans la musique, vraisemblablement déjà en développement in utero, va progressivement s’étendre au cadre de la conversation grâce aux interactions précoces entre l’adulte et l’enfant.
2. De l’émergence de la rythmicité et des prédictions dans l’interaction
En plus d’être sensible à la temporalité dans la musique et la parole, le bébé va développer une sensibilité accrue à la temporalité de l’interaction.
Quand un bébé émet un signal de communication, il s'attend à ce que l'adulte lui réponde mais dans un laps de temps bien spécifique : entre 1 et 2 secondes (voir Keller, Lohaus, Völker, Cappenberg, & Chasiotis, 1999). Cette capacité de l’adulte à répondre dans un temps imparti aux initiatives de l’enfant est appelée contingence temporelle. Si ce temps de réponse n'est pas respecté, le bébé semble ne pas considérer les comportements de l'adulte comme inscrits dans un espace intersubjectif commun ; autrement dit, il ne ressent pas que l’adulte lui prête des intentions de communication et risque de ne pas développer ses compétences langagières de manière optimale. La contingence temporelle des réponses de l’adulte conditionne en effet le développement des vocalisations du bébé (Kuhl, 2012) ainsi que celui des comportements linguistiques de plus en plus complexes du jeune enfant (M. H. Goldstein, King, & West, 2003; Michael H. Goldstein & Schwade, 2008). Lorsque des bébés âgés de 6 à 12 semaines interagissent en temps réel avec leur mère à travers une télévision, puis que l’on insère un délai de seulement une seconde dans la transmission de l’image de la mère, les bébés se désintéressent de l'interaction. En effet, du fait de l'interaction directe, les mères conservent bien une attitude souriante et bienveillante et adressée au même enfant mais ne répondent pas, à cause du délai de transmission de l’image, de manière contingente aux actions et productions du bébé, ce qui engendre chez ce dernier un arrêt de l'interaction ici manifesté par une réduction du taux des regards vers la vidéo (Henning & Striano, 2011; Nadel, Carchon, Kervella, Marcelli, & Reserbat-Plantey, 1999). Les bébés âgés de 3 et 4 mois, produisent en outre des vocalisations plus similaires à des sons de la parole (versus des bruits de bouche) quand les réponses de l'adulte sont temporellement contingentes à leurs productions. De plus, dans cette condition, leurs vocalisations sont séparées par de longs intervalles. Le délai plus important laissé par le bébé entre deux vocalisations suggère, que dans la situation où l’adulte fournit des réponses temporellement contingentes, il considère que l’adulte a l’intention d’échanger avec lui et s’attend, dans ce cadre-là seulement, à une probable réponse de sa part (Masataka, 1993).
La sensibilité temporelle et les prédictions précoces développées par le bébé dans le cadre interactionnel pourraient expliquer comment les enfants parviennent à se coordonner avec un adulte qui interagit avec eux. Autour de deux mois, le bébé est en effet capable de produire des vocalisations en alternance avec la parole de l’adulte en marquant des pauses régulières de 500 ms à 1 seconde entre les échanges (Jaffe, Beebe, Feldstein, Crown, & Jasnow, 2001). Une récente étude (Dominguez, Devouche, Apter, & Gratier, 2016) a révélé que dès 2 à 4 jours de vie, les nouveau-nés sont eux-aussi capables de s’engager dans des échanges de vocalisations avec leur mère, marqués par une véritable alternance. Ainsi, ces bébés vocalisent la plupart du temps dans la seconde qui suit l’arrêt des vocalisations de la mère et lui répondent même souvent dans les 50 ms qui suivent la fin de son tour de parole. Ce résultat suggère que les nouveau-nés sont déjà capables d’anticiper la fin du tour de leur mère avec précision. En outre, l’analyse de l’organisation temporelle de ces échanges préverbaux, montre que lorsque la mère est contingente, le bébé s'implique activement dans les échanges qui prennent alors l’allure de véritables tours de parole.
Ces échanges précoces entre l’adulte et l’enfant, même s’ils ne sont pas encore constitués de productions verbales sont suffisamment structurés temporellement pour que l’on perçoive en effet l’émergence de ce qui va devenir le tour de parole. Néanmoins, comme nous l’avons vu au chapitre 2, le tour de parole est une activité qui demande d’importantes capacités d’anticipation et d’adaptation liées en partie à la maturation du système sensori- moteur. La capacité à se coordonner dans le tour de parole va donc s’affiner progressivement grâce aux nombreux ajustements que la mère va mettre en place au cours des échanges précoces et aux différents partenaires conversationnels que va rencontrer l’enfant (Casillas, 2014). Ainsi, chez des enfants âgés de 7 à 18 mois, la proportion de chevauchements (i.e. les vocalisations de l’enfant produites en même temps que la parole de l’adulte) tend à diminuer avec l’âge, en particulier vers 12 mois, âge auquel les vocalisations seront produites en alternance dans des proportions plus importantes (Ginsburg & Kilbourne, 1988). Une autre étude longitudinale, menée sur des enfants âgés de 3 à 18 mois en interaction avec leur mère a montré que le pourcentage de chevauchements diminue avec l’âge mais plus précisément que ce pourcentage se réduit presque de moitié entre 3 et 9 mois (Gratier et al., 2015) pour devenir identique à celui de la mère à l’âge de 18 mois. Ce résultat, obtenu avant 9 mois, suggère que la réduction du pourcentage de chevauchements ne peut pas être attribuable à une augmentation de la compréhension des paroles de l’adulte par l’enfant mais plutôt à la capacité de l’enfant à s'inscrire dans une véritable temporalité de l’alternance dans l’interaction. En outre, un autre résultat de cette étude montre que lorsque les enfants alternent leurs vocalisations avec celles de l’adultes, la durée des silences entre les tours est plus courte à 5 mois comparée à 9 et 12 mois ce qui pourrait signifier qu'avant 9 mois, les enfants répondent à l’adulte dans un “simple” jeu d’alternance temporelle de donner- recevoir, mais qu’à partir 9 mois, âge de l’apparition de l’attention conjointe, entre en jeu le développement de compétences sémantiques qui ralentissent leur temps de réponse et augmente la durée des silences entre les tours. L’échange semble, à partir de cette période, être considéré par l’enfant comme un espace pour partager des informations sur le monde environnant, les objets et sur les émotions.
Le bébé possède donc bien, dès quelques jours de vie, des capacités de coordination temporelles avec l’adulte lors d’une interaction. Même si au cours du développement, l’alternance vocale bébé/adulte est soumise à des variations temporelles dues à l’émergence de capacités linguistiques, il n’en reste pas moins que cette alternance n’est possible que si le bébé est capable d'anticiper une réponse de la part de l’adulte et plus précisément la fin de son tour de parole. Pour permettre à l’enfant d’anticiper au mieux la réponse de l’adulte d’un point de vue temporel, ce dernier va systématiquement réajuster son comportement verbal ou non verbal en fonction des réponses de son enfant, afin que l’échange conserve un certain degré de rythmicité. En effet, contrairement à l’enfant, la mère va être très “permissive” quant aux variations de contingences temporelles de l’enfant (Henning & Striano, 2011; Striano & Stahl, 2006) dont les réponses peuvent être jusqu’à 10 fois plus longues chez les enfants de 3 ans et 5 ans par rapport aux moyennes des latences de réponses des adultes (Berninger & Garvey, 1981; Lieberman & Garvey, 1977 cité dans Casillas et al., 2015). Autrement dit, la mère va poursuivre l’échange même si son enfant ne produit pas une réponse contingente et va se réajuster afin que l’échange conserve une régularité permettant le développement de prédictions temporelles chez l’enfant.
Des études utilisant la technique de la poursuite des mouvements oculaires (eye- tracking) ont pu mettre en évidence les capacités d’anticipation des jeunes enfants dans le tour de parole. Le paradigme expérimental de ces études consiste à équiper les enfants d’un système d’eye-tracking et de leur présenter un dialogue entre deux personnages ou des marionnettes. La mesure des mouvements oculaires permet d’analyser à quel endroit l’enfant porte son regard au cours du dialogue et plus particulièrement au moment où les interlocuteurs vont changer de tour de parole. Si l’enfant regarde le locuteur qui va prendre son tour de parole alors que le locuteur précèdent n’a pas encore terminé son énoncé mais s’apprête à le faire, c’est probablement qu’il a anticipé la fin du tour de parole du locuteur en cours (voir figure 3.2). Une première étude réalisée par Keitel et collaborateurs (2013) a montré que parmi quatre groupes d’enfants âgés de 6-12-24 et 36 mois, seuls ceux de 36 mois étaient capables d'orienter leur regard par anticipation sur le locuteur à venir (Keitel, Prinz, Friederici, Hofsten, & Daum, 2013). Une étude de Casillas et Franck (2017) a montré, à l’aide du même type de paradigme que les enfants sont capables d’anticipation à partir de deux and et que cet effet plus marqué sur les paires de questions-réponses, augmente avec l’âge. Autrement dit, dès 2 ans, les enfants seraient capables de prédire que le locuteur en cours va terminer son tour de parole et cette anticipation serait facilitée lorsque le locuteur en cours pose une question qui appelle une réponse de la part de l’interlocuteur ; ce type de paires d’actes de parole est en effet hautement prédictible (Casillas & Frank, 2017). Contrairement aux adultes qui se basent essentiellement sur des indices lexico-syntaxiques (De Ruiter et al., 2006; ; voir aussi Keitel & Daum, 2015 pour un résultat différent), les enfants s’appuieraient, en fonction de leur âge développemental, sur une association d’indices lexico- syntaxiques et prosodiques pour anticiper la fin du tour de parole (Casillas & Frank, 2017; Keitel & Daum, 2015).
Figure 3.2. Représentation de la mesure de l’anticipation temporelle des enfants, lors de l’observation de dialogues adaptée de Casillas et Franck (2017). La marionnette n°1 parle pendant que la marionnette n°2 écoute. Dans le cas d’une anticipation du tour de parole, l’enfant, équipé d’un eye-tracker, va déplacer et fixer son regard sur la marionnette n°2 alors que la marionnette n°1 n’a pas encore terminé de parler ; c’est ce que représentent les points de couleur bleue, violette et rouge sur la marionnette n°2.
En résumé, les jeux de tours de parole/rôle avec l’adulte dans lesquels le bébé s’inscrit sont au départ maintenus sans une volonté de partager des informations avec l’adulte, mais ces jeux de donner-recevoir sont néanmoins temporellement structurés et établissent le cadre dans lequel vont émerger chez l’enfant des acquisitions linguistiques de plus en plus complexes. Autrement dit, c’est dans ce cadre interactionnel où se construit une synchronie interactionnelle, que l’enfant et l’adulte vont pouvoir partager des représentations temporelles et conceptuelles communes.
IV. Les capacités de prédictions des enfants sourds, une pièce manquante dans l'explication des déficits perceptifs des enfants sourds
Les enfants sourds congénitaux, implantés cochléaires, sont une population vulnérable en termes de perception et production du langage, et plus particulièrement en situation d’interaction. En effet, même si l’implant cochléaire améliore considérablement la perception de la parole, les niveaux de langage atteints par ces enfants demeurent très hétérogènes et certaines situations de communication détériorent les résultats obtenus en cabine audiométrique ou en face à face au calme, avec un seul interlocuteur. Dans ce chapitre, nous allons décrire le fonctionnement technique de l’implant cochléaire (IC) ainsi que les limitations perceptives dues à cette technologie. Nous décrirons ensuite l’évolution et les difficultés langagières des enfants implantés cochléaires ainsi que les possibles causes de l’hétérogénéité des niveaux de langage retrouvés post-implantation. Enfin, nous relaterons les quelques études qui ont analysé les effets d’une stimulation musicale sur les capacités de perception et de production de la parole chez les enfants implantés cochléaires.
1. Mise en place, fonctionnement et perception auditive avec un l’implant cochléaire
La surdité congénitale touche environ une naissance sur 1000. Parmi ces surdités, la surdité profonde touche 84 % des enfants sourds. Suite au dépistage qui a lieu en maternité à 3 jours de vie puis au diagnostic réalisé à l’hôpital ou en cabinet libéral en moyenne entre 3 et 6 mois de vie, les enfants dont les familles en font le choix, sont équipés de prothèses auditives conventionnelles pendant une durée de 4 à 6 mois. Cet appareillage par voie aérienne stéréophonique qui sera posé en rétro auriculaire si le bébé tient sa tête ou en Y si ses pavillons sont mous, permet de retransmettre sans les déformer et en les amplifiant, les signaux acoustiques émis dans l’environnement. A la fin de ces 6 mois de port de la prothèse conventionnelle et suite à un bilan réalisé par une équipe pluridisciplinaire incluant orthophonistes, audioprothésistes, psychologues et médecin ORL, une implantation cochléaire et une prise en charge peuvent être proposées à la famille. L’implantation est acceptée par la famille, elle sera réalisée en moyenne avant l’âge de 2 ans. La plupart des enfants atteints de surdité profonde et sévère seront opérés sur une seule oreille et porteront un implant avec ou sans prothèse controlatérale sur l’oreille non opérée. Dans des cas de cophose bilatérale, de surdité évolutive ou de risque d’ossification de la cochlée suite à une méningite, les enfants se verront équipés de deux implants posés de manière simultanée mais le plus souvent, cette double implantation se fera de manière séquentielle. L’implant cochléaire (figure 4.1) à la différence de la prothèse conventionnelle, nécessite une opération chirurgicale lors de laquelle le chirurgien insère à l'intérieur de l’organe sensoriel de l’oreille, la cochlée, une rangée d’électrodes (4) ; le nombre d’électrodes varie en général de 12 à 22 électrodes. Ces électrodes vont avoir pour fonction de transmettre des impulsions électriques au nerf auditif (en jaune sur la figure) qui enverra ensuite ces informations au cerveau. Les impulsions électriques proviennent d’un processeur (1) posé sur l’oreille de l’enfant qui transforme les sons de l’environnement en signal électrique en privilégiant les fréquences émises par la parole qui s’étalent entre 125 et 8000 Hz.

Figure 4.1. Représentation de l’oreille et de l’implant cochléaire extraite du site voyage au centre de l’audition. http://www.cochlea.eu/rehabilitation/implants-cochleaires
Le signal, envoyé au nerf auditif via l’implant cochléaire est bien différent de celui envoyé par la prothèse conventionnelle. L’implant cochléaire, contrairement à la prothèse “se substitue” aux fonctions de l’oreille dont le rôle est de transformer les informations acoustiques qui entrent dans le conduit auditif externe (5) en informations mécano- électriques ; cette transformation réalisée par une oreille saine permet entre autres de fournir des informations redondantes pour le codage et une perception précise des fréquences. L’oreille interne utilise en effet deux stratégies pour coder les fréquences contenues dans les stimuli acoustiques : le codage spatial dit “de place”, lors duquel les sons parvenus au tympan vont activer, via les mouvements d’une membrane contenue dans la cochlée (membrane basilaire), environ 3500 cellules sensorielles (pour les cellules ciliées internes) réparties tout le long de la cochlée. Ces cellules vont coder différentes fréquences (de 20 à 20000 Hz) en fonction de leur emplacement le long de la cochlée. Ainsi, les sons avec des fréquences graves seront codés par les cellules situées à l’apex de la cochlée (6) alors que les sons aigus seront codés par les cellules situées à sa base (7). Cette répartition spatiale des cellules ciliées en fonction des fréquences est nommée tonotopie et se retrouve également tout le long des voies auditives jusqu’au cortex auditif primaire (aire 41 de Brodmann). L’autre stratégie utilisée par l’oreille pour le codage des fréquences est la stratégie temporelle dite “principe de la volée”, lors de laquelle les neurones du nerf auditif se synchronisent sur la période ou sur des multiples entiers de la période du stimulus acoustique. Cette autre stratégie a cependant des limites physiologiques qui ne permettent pas de percevoir la fréquence au-delà de 5000 Hz. Ces deux types de stratégies se complètent pour permettre une perception précise de la hauteur des sons qui permet de discriminer les différents tons dans la musique ou les subtiles variations prosodiques dans la parole. Elles permettent également de traiter la structure dite “fine” de la parole grâce à laquelle nous pouvons discriminer des phonèmes qui diffèrent en termes de lieu d’articulation ou de voisement (cf. partie n°1 pages 13) ou de percevoir la parole dans le bruit.
Du fait de ses caractéristiques techniques, l’implant cochléaire limite beaucoup l’utilisation de ces deux stratégies du codage des fréquences. En effet, l’implant va séparer le signal acoustique en différentes bandes de fréquences puis extraire l’enveloppe temporelle du signal obtenu. Autrement dit, l’implant va extraire les variations d’amplitude lentes du signal acoustique (2 à 50 Hz) mais pas la structure fine. Après une étape de compression, l’enveloppe temporelle sera transmise aux électrodes qui enverront les impulsions au nerf auditif. Ces électrodes, bien que respectant la tonotopie de la cochlée ne sont qu’au nombre de 22 (nombre maximum contre 3500 cellules ciliées internes) et ne vont donc permettre qu’une transmission imprécise des fréquences contenues dans le signal acoustique.
L’implant cochléaire réduit également le codage des variations d’intensité contenues dans le signal. Ainsi, s’il est possible de discriminer de 60 à 100 paliers différents sur une échelle de 0 à 120 dB pour une oreille saine l’implant cochléaire ne permet de discriminer seulement 20 paliers pour une échelle de 6 à 30 dB (pour plus de détails voir Limb & Roy, 2014).
Même si l’implant cochléaire favorise le codage des bandes de fréquences contenues dans la parole, il ne permet pas de percevoir le timbre vocal qui dépend d’une association du codage des informations fréquentielles, temporelles et d’intensité (codage spectral) mais il limite également la perception des informations prosodiques et des informations phonétiques relavant d’indices temporels rapides. Ces limitations vont avoir des conséquences sur la perception du langage et particulièrement dans les situations d’écoute nécessitant de séparer plusieurs flux acoustiques produits simultanément (cocktail party).
Ces limitations de codage de l’information acoustique et en particulier de la structure fine vont en outre dégrader l’appréciation de la musique par les personnes implantés cochléaires, en tout cas pour celles qui sont devenues sourdes et qui ont eu un passé auditif musical sans implant cochléaire. L’implant va limiter le seuil de discrimination des tons (½ ton pour une personne normo-entendante contre 1 à 8 demi-tons pour les personnes IC) et ainsi engendrer chez les personnes implantées cochléaires des difficultés à identifier les variations mélodiques de la musique (combinaison séquentielle des tons) surtout lorsque les tons présentés sont des tons complexes comparé à des tons purs (Galvin, Fu, Shannon, & Shannon, 2009). L’IC va aussi limiter l’appréciation de l’harmonie (combinaison simultanée des sons). La perception du timbre musical va également être altérée et engendrer chez la personne implantée cochléaire des difficultés à discriminer différents instruments. Cependant, les paramètres technologiques de l’implant ne semblent pas limiter la perception des informations temporelles musicales telles que le rythme. Les adultes devenus sourds implantés cochléaires se basent d’ailleurs sur le rythme musical pour reconnaître ou discriminer des mélodies (Kong, Cruz, Jones, & Zeng, 2004). On sait en outre que les enfants sourds congénitaux implantés cochléaires fournissent une reproduction plus fidèle des caractéristiques temporelles des chansons comparé à leurs caractéristiques fréquentielles lorsqu’ils chantent des chansons connues (Nakata, Trehub, Mitani, & Kanda, 2006).
2. Conséquences de la surdité et de l’implantation cochléaire sur le développement du langage
Bien que dans l’ensemble, l’implantation précoce dans le cadre d’une surdité congénitale permette aux enfants sourds profonds d’intégrer des écoles ordinaires et de vivre dans un milieu entendant, les résultats des études montrent que leurs niveaux de langage sont assez hétérogènes. Malgré de nombreuses recherches sur la source de cette variabilité, il demeure difficile de déterminer quel (s) est (sont) le (s) prédicteur (s) d’un bon niveau de langage post-implantation (van Wieringen & Wouters, 2015).
On sait que l’implantation, en particulier l’implantation avant l’âge de 2 ans permet aux enfants sourds profonds d’obtenir des niveaux de langage plus proches de ceux de leurs pairs normo-entendants comparé aux résultats obtenus à partir de prothèses conventionnelles (Geers, 1997; Truy et al., 1998). Parmi les enfants implantés cochléaires, l’âge d’implantation, les stratégies de codage de l’information acoustique par l’implant, le mode de communication, mais également le respect par les familles des étapes chronologiques menant du dépistage à la prise en charge précoce (1-3 et 6 mois aux Etats- Unis) sont évoqués comme de possibles prédicteurs des scores de langage post-implantation (Dowell, Dettman, Blamey, Barker, & Clark, 2002; Yoshinaga-Itano, Sedey, Wiggin, & Chung, 2017). L’âge d’implantation et la durée du port de l’IC semblent être de bons prédicteurs avec un effet particulièrement important sur les scores de langage en perception et production (Dettman et al., 2016). Niparko et collaborateurs (2010) ont évalué le développement linguistique sur 3 ans d'une grande cohorte d’enfants implantés avant 5 ans (N= 188) et recrutés dans 6 centres d’implantation différents. Des mesures langagières en expression et compréhension, des mesures de reconnaissance de la parole mais aussi de la quantité des interactions parent-enfant ont été collectées à 6-12-24 et 36 mois post-implantation. Ces mêmes mesures ont été relevées chez un groupe contrôle d‘enfants normo-entendants. Les résultats confirment l’effet d’une implantation précoce et de la durée de la déprivation sensorielle sur la rapidité du développement du langage. L’audition résiduelle, le taux d‘interactions parent-enfant et le niveau socio-économique des familles sont également des facteurs associés à l’amélioration des capacités linguistiques au cours du temps (Niparko et al., 2010).
L’implant cochléaire peut ainsi permettre aux enfants sourds de considérablement améliorer leur niveau de langage en 3 ans, mais il ne leur permet pas toujours de rattraper le niveau de leurs pairs normo-entendants (Boons et al., 2013; Geers, Nicholas, & Sedey, 2003; Niparko et al., 2010). Même équipés d’un implant cochléaire bilatéral, les enfants obtiennent des résultats très variables en termes de niveaux de langage et ces différences inter- individuelles ne seraient pas expliquées par la durée du port de l’un ou des deux implants, ni par le niveau d’éducation des familles (Hess, Zettler-Greeley, Godar, Ellis-Weismer, & Litovsky, 2014).
Plus précisément, comparé aux scores de leurs pairs normo-entendants, les enfants sourds IC présentent des déficits en fluence verbale phonologique et sémantique (Wechsler- Kashi, Schwartz, & Cleary, 2014) ainsi qu’en compréhension lexicale. Un niveau de langage plus particulièrement affecté est le niveau de production et de compréhension morphosyntaxique ; ces difficultés semblent liées à des déficits d’attention auditive. En effet, les scores de compréhension morphosyntaxique sont encore plus faibles lorsque les tâches nécessitent la discrimination de mots proches d’un point de vue phonologique (Caselli, Rinaldi, Varuzza, Giuliani, & Burdo, 2012). Les déficits en compétences syntaxiques semblent avoir un impact négatif sur les compétences métacognitives des enfants implantés telles que l’accès à théorie de l’esprit ou encore sur le développement de la compréhension en lecture (Lederberg et al., 2013). Des compétences linguistiques plus élaborées telles que la compétence narrative (Boons et al., 2013), discursive ou le raisonnement verbal abstrait sont des domaines où l’enfant sourd, même implanté cochléaire, rencontre des difficultés comparé à ses pairs normo-entendants (Geers, Moog, Biedenstein, Brenner, & Hayes, 2009; Geers & Sedey, 2011). La prosodie est un autre niveau de langage particulièrement déficitaire chez l’enfant implanté cochléaire. Comme expliqué dans la première partie de ce chapitre, le codage de l’information acoustique par l’implant cochléaire réduit drastiquement le nombre et la précision des fréquences perçues, ce qui se traduit par des limitations dans la perception fine des indices prosodiques. Les enfants implantés cochléaires, comparé à leurs pairs normo-entendants, présentent en effet plus de difficultés dans les tâches de discrimination d’intensité, de durée et de fréquence fondamentale. Ces difficultés sont associées à des scores plus faibles que le leurs pairs normo-entendants dans des tâches de discrimination de mots et de phrases en fonction de l’accent (Torppa, Faulkner, et al., 2014). Par ailleurs, la capacité à discriminer des énoncés sur la base des émotions contenues dans la voix est faible voire impossible (pour la colère versus la joie et la tristesse) chez des enfants implantés âgés entre 5 et 13 ans comparé à un groupe d’enfants normo-entendants (Nakata, Trehub, & Kanda, 2012 ; voir également Jiam, Caldwell, Deroche, Chatterjee, & Limb, 2017). Les adolescents implantés cochléaires utilisent aussi moins efficacement que les adolescents normo- entendants (NE) les indices prosodiques dans un contexte discursif. Les adolescents IC ont en effet plus de difficultés que les adolescents NE à prévoir, compte-tenu des indices prosodiques contenus dans le contexte discursif, l’accent marquant le focus dans une phrase; ces difficultés sont marquées par des temps de réaction plus longs chez les implantés cochléaires lorsqu’ils doivent détecter un phonème-cible contenu dans la phrase (Holt, Demuth, & Yuen, 2016). Par ailleurs, les adolescents implantés cochléaires n’utilisent pas les informations prosodiques de la même manière que les adolescents normo-entendants ; ils utilisent des contours mélodiques opposés à ceux utilisés par les adolescents normo- entendants lors de la production des mêmes actes de parole (e.g. contour montant plus important sur les requêtes d’informations que sur les directives chez les adolescents NE et contour montant plus important sur les directives que sur les requêtes d’informations chez les adolescents IC) (Holt, Yuen, & Demuth, 2017). Un dernier niveau de langage, relativement peu exploré en surdité, est le niveau pragmatique qui peut être défini comme “une habileté à utiliser la parole et les gestes de manière appropriée en tenant compte du contexte et des besoins de son interlocuteur” (Stephens & Matthews, 2014, p.14). D’une manière générale, les enfants sourds présentent, comme pour les autres niveaux de langage des niveaux de performances hétérogènes (Bebko, Calderon, & Treder, 2003). Tye-Murray (2003) a spécifiquement analysé, via des conversations filmées, les capacités des enfants implantés cochléaires, âgés entre 8 et 9 ans, à conserver la fluidité d’une conversation. Leurs résultats montrent, que comparé aux enfants normo-entendants, les enfants implantés présentent plus de silences et de bris de communication lorsqu’ils conversent avec un adulte inconnu, en l’occurrence ici une orthophoniste (Tye-Murray, 2003). En outre, lorsqu’ils conversent avec un adolescent normo-entendant du même âge qui leur est familier, les adolescents implantés cochléaires présentent des capacités conversationnelles identiques aux adolescents NE en quantité mais différentes en qualité : les adolescents IC produisent des actes de parole différents de ceux produits par les adolescents NE lorsqu’ils conversent entre eux (i.e. plus de requête en clarification, moins de requête en confirmation et en élaboration) (Ibertsson, Hansson, Maki-Torkko, Willstedt-Svensson, & Sahlen, 2009). Les auteurs soulignent que ces scores sont à interpréter dans le contexte de la tâche qui est une tâche de communication référentielle, réalisée au calme, avec un adolescent normo-entendant connaissant l’adolescent sourd donc possiblement très adapté. Dans une autre tâche de communication référentielle (map task) réalisée avec un adulte étranger, les adolescents implantés cochléaires prennent moins la parole comparé aux adolescents normo-entendants, ils produisent moins d’acte de discours et marquent moins les frontières d’énoncés (Holt et al., 2017). Most et collaborateurs (2010) ont comparé, grâce à une grille d’analyse, le profil pragmatique d’enfants sourds implantés et appareillés avec des prothèses conventionnelles, à ceux d’enfants normo-entendants. Les résultats montrent un profil similaire entre enfants porteurs d’implants cochléaires et enfants porteurs de prothèses conventionnelles mais surtout une utilisation inappropriée des compétences communicatives, verbales et gestuelles, comparé à leurs pairs normo-entendants (Most, Shina-August, & Meilijson, 2010). Paatsch & Toe (2013) ont utilisé un contexte plus écologique que les études précédentes ; les auteurs ont mesuré les habiletés pragmatiques des enfants implantés cochléaires et appareillés avec des prothèses auditives conventionnelles (PC) à partir d’enregistrements de vidéos de conversations informelles entre les enfants sourds et leurs copains de classe normo-entendants, âgés entre 8 et 12 ans. Ils ont ensuite comparé ces mesures avec les mesures effectuées à partir des conversations des mêmes enfants normo-entendants mais entre eux. Les résultats montrent que lorsque les enfants sourds (avec PC et IC confondus) conversent avec un enfant normo-entendant, ils initient plus de sujet et présentent des tours de parole plus longs que leur partenaire contrairement aux paires d’enfants normo- entendants pour lesquelles les tours en termes d’initiation de sujet et de longueur, sont très bien équilibrés (Toe & Paatsch, 2013). La tendance des enfants implantés cochléaires à “dominer” la conversation, à moins se mettre à la portée de leur partenaire de communication, se retrouve dans les stratégies différentes qu’ils utilisent pour réparer les bris de communications lors d’une tâche de communication référentielle avec un inconnu. Dans cette tâche, les adolescents possèdent le tracer d’un itinéraire mais pas exactement la même carte que celui de leur partenaire. A partir de ce tracer, ils doivent guider leur partenaire inconnu afin qu’il puisse retrouver sa route. Comparé à leurs pairs normo- entendants qui vont rechercher l’information manquante chez leur partenaire pour l’aider à avancer lorsque ce dernier est perdu, les adolescents implantés cochléaires ont plutôt tendance à répéter les informations de direction qu’ils viennent de donner sans utiliser des stratégies qui leur permettraient de combler les informations manquantes chez leur partenaire (Holt et al., 2017).
Pour résumer, les enfants implantés cochléaires présentent des niveaux de langage supérieurs à ceux de leurs pairs utilisant des prothèses conventionnelles. Implantés avant 18 mois (ou 24 selon les études), ces enfants peuvent obtenir des résultats comparables à ceux de leurs pairs normo-entendants à des tests de langage en expression et compréhension. Grâce à l’implantation précoce, ces enfants bénéficieraient en effet d’une plus grande aptitude à apprendre le langage de manière incidente. Les acquisitions les plus lentes portent sur les domaines de la grammaire, de la syntaxe et la perception et production des informations morphologiques. Cependant, ces enfants présentent aussi des différences (par rapport aux normo-entendants) dans le traitement de la prosodie du langage et les compétences discursives et conversationnelles. La communication auditivo-verbale versus la communication totale (I.e. comprenant l’utilisation de la langue orale associée à l’utilisation de la langue des signes) semble avoir une influence positive sur les capacités de production du langage des enfants IC, analysées à partir de corpus de langage spontané. Cependant, ces études ne permettent pas de déterminer si les enfants ayant besoin d’une communication totale ne possèdent pas, au préalable, un déficit ou des processus de traitement différents des enfants n’ayant besoin que de la communication auditivo-verbale. Malgré ces résultats favorables à l’implantation et en particulier l’implantation précoce, les auteurs mettent en garde contre l’interprétation des moyennes des scores obtenus aux tests de langage en soulignant l’importante erreur standard relevée dans les données (voir aussi van Wieringen & Wouters, 2015) ainsi que les retards subsistants, pour plus de la moitié de la population des enfants implantés cochléaires, vis-à-vis des capacités linguistiques des enfants normo- entendants (cf. l'article de revue de Ganek, McConkey Robbins, & Niparko, 2012). Bien qu'environ 50 % de la variabilité des résultats obtenus par les enfants implantés cochléaire aux tests de langage puissent être expliqués par l’âge d’implantation (Geers, 2009 ; van Wieringen & Wouters, 2015), la différence d’organisation cérébrale et des processus de traitement retrouvés chez les enfants ayant souffert d’une déprivation auditive depuis leur naissance voire in utéro, pourraient expliquer, en partie, cette variabilité.
3. Conséquences de la surdité profonde congénitale sur le développement de l’organisation et du fonctionnement des structures cérébrales et des processus de traitement de l’information sensorielle
Plusieurs études sur l'animal et sur l'homme, réalisées en imagerie (en tomographie par émission de positron : PET scan) et en électrophysiologie (EEG), montrent que l'absence de stimulation auditive engendre une réorganisation cérébrale fonctionnelle (Lomber, Meredith, & Kral, 2010; Ponton & Eggermont, 2001). Le développement des aires cérébrales sensorielles, pré-existantes à la naissance, et les liens fonctionnels qui les relient, reposent en effet sur des périodes dites “sensibles” lors desquelles la création et le renforcement des synapses entre les neurones sont maximal. Si lors de ces périodes, la structure corticale ne reçoit un input sensoriel suffisant, en l'occurrence ici, si le cortex auditif ne reçoit pas de stimuli acoustiques, le développement de l’aire auditive primaire - aire qui traite les caractéristiques temporelles et fréquentielles des sons - et ses connexions avec les aires secondaires, qui attribuent des représentations aux sons, se désorganisent. Cette altération des connexions entre les aires auditives primaires et les aires de plus haut niveau de traitement ne permet pas la mise en place de voies cortico-fugales qui partent des cortex secondaires associatifs vers les cortex primaires et les aires sous-corticales (voir figure 4.2). Le développement de ces voies est important car elles sont la source de processus dits “top down” qui modulent la perception de stimuli auditifs que nous recevons. On sait par ailleurs que plus l’expérience auditive est importante, plus la modulation des stimuli auditifs sera rapide et précise (Lesicko & Llano, 2017). Le manque de modulation des représentations de haut niveau lors de la perception (processus toptown) altère les capacités de catégorisation et d'organisation des informations auditives nouvelles (Kral & Eggermont, 2007). Ainsi, même si les facteurs génétiques déterminent les connexions potentielles entre les structures cortico-sous-corticales et cortico-corticales, c’est bien la qualité des stimulations et de l’expérience auditive qui va par la suite façonner et établir une stabilité de ces connexions, source de processus de traitement efficaces du langage (voir article de revue Kral, Yusuf, & Land, 2017).
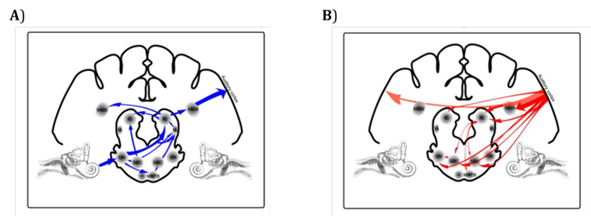
Figure 4.2. Représentation des voies auditives afférentes bottomup et cortico fugales – topdown extraite de Kral et Eggermont (2007). Panel A) Depuis le nerf auditif, l’influx nerveux est transmis aux différents relais du tronc cérébral et arrive au cortex auditif primaire puis secondaire. Panel B) Depuis le cortex auditif, l’influx nerveux redescend vers le tronc cérébral pour moduler la réponse nerveuse en périphérie.
Plus précisément, les études révèlent différents marqueurs qui signent l’impact d’une déprivation auditive sur l’organisation fonctionnelle du système auditif.
Ainsi, la latence et la forme de l’onde P1, qui reflètent la durée et la qualité de la propagation de l’information électrique du tronc cérébral au cortex auditif primaire - autrement dit la maturation des voies auditives - est considérablement retardée et déformée chez les enfants implantés cochléaires après 7 ans (Sharma, Dorman, & Spahr, 2002a, 2002b; Sharma, Spahr, Dorman, & Todd, 2002). Contrairement aux enfants implantés avant 3,5 ans, chez les enfants implantés tardivement, la latence de l’onde P1, qui apparaît, à la naissance, 300 ms post-stimulation puis passe à 100 ms à 2 ans et enfin entre 50 et 70 ms à l’âge adulte, ne parvient jamais à atteindre celle des enfants normo-entendants (Sharma, Gilley, Dorman, & Baldwin, 2007) (voir figure 4.3).
Alors que l’onde P1 est générée dans le cortex auditif primaire, la source du complexe N1/P2 se trouverait dans le cortex auditif secondaire, de plus haut niveau. Le développement de ce complexe N1/P2 est associé à une augmentation du couplage cortico-cortical (entre les aires auditives primaires et les aires auditives secondaires) et une augmentation du traitement auditif et du langage (voir Chapitre 3 Eggermont & Moore, Human Auditory Development, 2012). Alors que les enfants implantés avant 3,5 ans développent ce complexe N1/P2 à l’adolescence comme les adolescents normo-entendants (voir figure 4.3 panel K) et panel B) respectivement), les enfants implantés tardivement ne développent jamais ce complexe (voir figure 4.3 panel L). Le découplage entre les aires auditives primaires et secondaires chez ces enfants pourrait expliquer leurs difficultés à attribuer du sens aux perceptions reçues via l’implant cochléaire. En outre, comme l’expliquent Sharma et al. (2015), le découplage entre les cortex auditifs primaires et secondaires va engendrer une réorganisation corticale : les inputs sensoriels provenant de la modalité visuelle et somatosensorielle vont “coloniser” les voies reliant les aires auditives primaires et secondaires et c’est ainsi que les cortex auditifs secondaires vont être activés chez des adultes sourds, lors de la présentation de stimuli visuels ou somatosensoriels. La réorganisation des voies fonctionnelles existant à l’intérieur et entre les cortex sensoriels semble corrélée aux résultats retrouvés en langage même chez des enfants implantés précocement (Sharma, Campbell, & Cardon, 2015). Lors d’une récente étude, Feng et collaborateurs (2018) ont développé un modèle permettant de prédire les scores de langage des enfants futurs implantés cochléaires. A partir des données IRM pré-implantation, les auteurs ont comparé les données neuroanatomiques des enfants candidats à l’implantation à celles d’enfants normo-entendants du même âge. Ils ont ainsi pu observer les différences de densité de matière grise et blanche et de réseaux fonctionnels entre les deux populations et établir les régions qui avaient été affectées par la déprivation sensorielle. Les auteurs ont également mesuré l’amélioration de la perception auditive et les compétences linguistiques des enfants avant l’implantation et à 6 mois post-implantation. Dans ce modèle, l’âge, le sexe, la classe socio-économique des parents, la latéralisation de l’IC, l’audition résiduelle et les différences et similitudes neuroanatomiques entre enfants sourds et enfants normo-entendants ont été entrées comme prédicteurs des capacités perceptives et linguistiques des enfants futurs candidats à l’implant. Les résultats montrent que ce ne sont pas les régions affectées par la déprivation sensorielle qui prédisent le mieux l’amélioration de la perception et des compétences linguistiques après implantation mais les régions cérébrales qui sont restées identiques à celles des enfants normo-entendants malgré la déprivation auditive.
Autrement dit, ce n'est pas l’altération des régions auditives primaires mais la préservation des régions auditives et cognitives de haut niveau telles que le gyrus temporal supérieur, les cortex fronto-pariétal et la voie dorsale, reliant les structures auditives aux structures motrices, qui prédit le mieux les scores de langage des enfants implantés cochléaires. Ce réseau cognitif est en effet connu pour être hautement impliqué dans la perception de la parole (cf. partie 1 et 2) mais aussi dans le traitement séquentiel de l’information sensorielle.

Figure 4.3. Représentation du développement de l’onde P1 et du complexe P1/N1/P2 chez les enfants normoentendants et chez les enfants sourds en fonction de l’âge d'implantation extraite de Sharma et Kral (2012). Graphique n°1 : développement de l’onde P1 et du complexe P1/N1/P2 en fonction de l’âge chez les enfants normo-entendants. Les panels A), B) et C) représentent l’évolution de la maturation de ces différentes ondes. Graphique n°2 : Panel I) Les lignes noires représentent les limites des latences des enfants normo-entendants en fonction de l’âge. Les points de couleurs reliés par des lignes représentent le développement de la latence de l’onde P1 d’enfants implantés cochléaires à différents âges (voir la légende des âges sur la droite). On peut voir qu’avant 1, 5 ans ou 2 ans, tous les enfants implantés cochléaires, quel que soit l’âge d’implantation, ont des latences retardées, i.e. latences qui vont au-delà des limites de latences retrouvées chez les enfants normo-entendants. Mais les points verts, violet et noir, qui correspondent aux enfants implantés avant 3,5 ans, sont situés dès 6 à 8 mois post-implantation à l’intérieur de ces lignes ce qui signifie que ces enfants implantés précocement sont parvenus à rattraper les latences des enfants normo-entendants contrairement aux enfants implantés plus tardivement représentés par les points d’autres couleurs.
Certains auteurs pensent en effet que la déprivation auditive n’affecte pas seulement la perception et la production du langage mais également des processus neurocognitifs plus généraux (Houston et al., 2012). Des études mettent en évidence des déficits dans la formation de concepts (Castellanos, Pisoni, Kronenberger, & Beer, 2015) ainsi que dans des tâches impliquant les fonctions exécutives (Beer et al., 2014; Figueras, Edwards, & Langdon, 2008; Kronenberger, Pisoni, Henning, & Colson, 2013). Une autre compétence, semble affectée chez les enfants sourds implantés cochléaires. Conway et collaborateurs (2009) ont en effet émis l’hypothèse que la déprivation auditive n’affecterait pas seulement la perception auditive mais que celle-ci aurait des conséquences sur des habiletés cognitives liées à l’apprentissage implicite de séquences (Christopher M. Conway, Pisoni, & Kronenberger, 2009). L’apprentissage implicite est par exemple cette capacité qui nous permet d’apprendre de manière incidente une succession de mouvements ou d’évènement dans un ordre précis. Cet apprentissage de patterns d’actions nous permet de développer une compétence comme apprendre à jouer d’un instrument ou faire des prédictions sur le déroulement des évènements qui ont lieu habituellement dans notre environnement. Plusieurs études ont montré que cette compétence cognitive, générale à plusieurs domaines d’apprentissage, serait nécessaire au développement des compétences linguistiques (voir Deocampo, Smith, Kronenberger, Pisoni, & Conway, 2018 pour une revue de la littérature). Pour tester la présence ou l’absence de cette capacité chez les enfants sourds, Conway et collaborateurs (2011) ont présenté à des enfants implantés cochléaires ainsi qu’à des enfants normo-entendants une succession de stimuli visuels dont l’ordre d’apparition dépendait d’une grammaire artificielle. Dans une phase pré-test, les enfants ont appris de manière implicite l’ordre de présentation des stimuli. Dans la phase de test les enfants devaient rejouer les séquences apprises. Les auteurs ont analysé la précision du rappel des séquences à la fois lors de la présentation de séquences qui suivaient la grammaire artificielle mais aussi lors de la présentation de séquences qui suivaient un ordre aléatoire. Les résultats ont montré que les enfants sourds n’obtenaient pas de meilleures performances au rappel de séquences lorsque celles-ci étaient organisées selon une structure non aléatoire (i.e. qui suivaient les règles d’une grammaire artificielle) alors que les enfants normo-entendants ont bénéficié de cette organisation des séquences comparé à la condition ou les séquences suivaient un ordre aléatoire. Les auteurs en ont conclu que les enfants ayant souffert d’une déprivation auditive présentaient des déficits d’apprentissage implicite de séquences dans toutes les modalités sensorielles (Conway, Pisoni, Anaya, Karpicke, & Henning, 2011). Mais d’autres auteurs (Hall, Eigsti, Bortfeld, & Lillo-Martin, 2017; Torkildsen, Arciuli, Haukedal, & Wie, 2018) ont émis des réserves quant à la différence de l’effet retrouvé entre les deux populations et au type de paradigme utilisé. Hall et collaborateurs (2017) ont ainsi tenté de répliquer l’étude de Conway et collaborateurs (2011) mais sur trois populations différentes : des enfants sourds signants, des enfants sourds avec implants cochléaires et des enfants normo-entendants. Ils ont ensuite testé ces trois populations sur les mêmes compétences d’apprentissage implicite mais à partir d’une tâche de temps de réaction en série (Serial Reaction Time : SRT). La réplication de l’étude Conway (2011) ne montre pas les mêmes résultats : aucune des trois populations ne présente des capacités d’apprentissage implicite suite à la tâche basée sur l’apprentissage d’une grammaire artificielle. Les résultats obtenus suite à la tâche de SRT montrent par contre que les trois populations possèdent de robustes capacités d’apprentissage implicite et qu’il n’y a pas de différence entre les trois populations (Hall et al., 2017). von Koss Torkildsen et collaborateurs (2018) ont voulu répliquer ces études en utilisant une tâche d’apprentissage implicite impliquant, entre autre, moins de stratégies de rappel verbal que la tâche de Conway (2011) et les résultats montrent des capacités d’apprentissage implicite identiques chez les enfants implantés cochléaires et les enfants normo-entendants. Cependant, même si ces enfants développent des capacités d’apprentissage implicite identiques aux enfants normo-entendants, il semble néanmoins que la déprivation auditive engendre des déficits d’attention précoces à la parole (à 1 et de 3 à 6 mois post-implantation) qui ne sont pas expliqués par les données démographiques habituellement corrélées telles que l’âge d’implantation, la quantité d’audition résiduelle ou le mode de communication (Wang, Shafto, & Houston, 2018).
Il semble donc difficile de déterminer avec précision la cause de la variabilité des résultats retrouvés dans les profils linguistiques des enfants implantés cochléaires, néanmoins, à la lumière des données d’imagerie cérébrale et électrophysiologiques il semble que les structures corticales de haut niveau, impliquées dans des opérations cognitives générales, soit en partie responsables des déficits perceptifs et linguistiques retrouvés chez ces enfants même implantés précocement. Cependant, comme expliqué aux chapitres 1 et 2, la pratique de la musique favorise la stimulation de plusieurs opérations cognitives en partie utilisées lors du traitement du langage mais également l’activation des aires cérébrales de haut niveau et notamment les connexions fonctionnelles entre les aires auditives et les aires motrices, impliquées dans l’attention et perception de la parole.
Nous allons montrer dans cette dernière partie que la musique peut avoir un effet sur la perception et la production du langage des enfants sourds.
4. Effet de la stimulation musicale sur la perception auditive et la production de la parole chez l’enfant sourd
Bien que la musique soit utilisée en rééducation par des orthophonistes musiciennes et non musiciennes à des fins de découverte des styles musicaux, des timbres des instruments, des différents paramètres sonores, de la mise en musique d’émotions jouées par des personnages de fictions, elle est encore très peu utilisée à des fins de rééducation du langage. Pourtant, de plus en d’études et d’articles de revue recommandent l’utilisation de la musique dans les prises en charge et en particulier dans la rééducation du langage (François, Grau-Sánchez, Duarte, & Rodriguez-Fornells, 2015; Fujii & Wan, 2014; Thaut, McIntosh, & Hoemberg, 2015). Quelques études analysant les effets de transfert d’un entrainement musical sur les compétences langagières des personnes porteuses d’un implant cochléaire commencent aussi à voir le jour. La plupart de ces études sont réalisées chez des adultes post linguaux (voir par exemple Fuller, Galvin, Maat, Başkent, & Free, 2018) et quelques-unes commencent à être réalisées chez les enfants sourds congénitaux.
Deux études ont testé les effets d’un amorçage musical de type rythmique sur les compétences langagières des enfants sourds congénitaux implantés cochléaires. Une première étude de Cason et collaborateurs (2015) a analysé la qualité de la répétition de phrases chez un groupe d’enfants sourds implantés cochléaires et appareillés de manière conventionnelle directement après l’écoute et la reproduction d’une structure rythmique musicale. Ils ont comparé le pourcentage de voyelles, consonnes, syllabes et mots répétés sans l’amorçage et après l’amorçage ; la structure métrique de cet amorçage pouvant correspondre ou pas à la structure métrique des phrases à répéter. Les résultats montrent que d’une manière générale, les enfants sourds obtiennent de meilleures performances de répétition après l’amorçage versus aucun amorçage et ce, que l’amorce soit identique ou pas à la phrase en termes de structure métrique. Cependant, cet effet est retrouvé plus important chez les enfants implantés cochléaires comparé aux enfants appareillés de manière conventionnelle (Cason, Hidalgo, Isoard, Roman, & Schön, 2015). Selon le même type de protocole expérimental, Bedoin et collaborateurs (2017) ont testé, chez des enfants sourds congénitaux implantés cochléaires, les effets d’un entrainement morphosyntaxique après un amorçage musical de type rythmique (8 sessions de 20 minutes) et après un amorçage auditif à partir de sons environnementaux sans structure rythmique (8 sessions de 20 minutes). Les auteurs ont réalisé des mesures de compréhension syntaxique et de jugement grammatical ainsi que des mesures de répétition de non-mots, d’attention visuo-spatiale et de mémoire avant les entrainements, après le premier entrainement et après le deuxième entrainement. Les résultats montrent que quel que soit le type d’amorçage qui précède l’entrainement, les enfants implantés cochléaires, âgés de 7 ans en moyenne, améliorent leurs performances dans les jugements grammaticaux, le traitement de la syntaxe, la répétition de non-mots et l’attention mais que la différence de performances dans les jugements grammaticaux et la répétition de non-mots est plus importante après l’entrainement précédé d’une amorce musicale qu’après celui précédé d’une amorce auditive (Bedoin et al., 2017). Les deux études décrites ci-dessus ont mesuré les effets d’un entrainement musical à court terme (amorçage) sur les compétences langagières, mais d’autres études ont étudié les effets d'un entrainement musical de plus longues durées.
Torppa et collaborateurs (2014) ont par exemple évalué de manière indirecte, les effets d’une pratique musicale régulière sur les compétences linguistiques des enfants implantés cochléaires. Dans cette étude, les auteurs analysent trois groupes d’enfants : un groupe d’enfants normo-entendants, un groupe d’enfants implantés cochléaires et un groupe d’enfants implantés pratiquant une activité musicale à l’école, dans une association ou ayant pratiqué une activité musicale avec ses parents à un plus jeune âge. Ils comparent ces trois groupes d’enfants sur une tâche de discrimination d’accents dans les mots, de discrimination de paramètres acoustiques (durée, intensité et fréquence fondamentale) et sur une tâche de mémoire de travail. Les résultats montrent que les enfants implantés ayant suivi une activité musicale ont de meilleurs résultats que ceux qui pratiquent une autre activité mais surtout qu’ils obtiennent des performances équivalentes à celles des enfants normo-entendants dans les tâches de discrimination de la F0, de la durée, de répétition de chiffres (i.e. mémoire de travail) et dans la tâche de perception de la prosodie (Torppa, Faulkner, et al., 2014).
Dans une méta-analyse récente Gfeller (2016), a recensé les quelques études qui ont évalué plus directement les effets de la pratique de la musique sur les capacités musicales et linguistiques des enfants implantés cochléaires. Selon l’auteur, il est difficile d’appréhender la taille des effets générés par les interventions car les méthodologies employées (contenu des stimulations : activités multimodales versus spécifiques, format des stimulations : approches pédagogiques holistiques en groupe versus individualisées et/ou à partir de programmes informatisés, fréquence et durée des stimulations : de 2 semaines à 2 ans), l’âge des participants, l’âge et la durée d’implantation, le type d’implant utilisé et la manière dont ces effets sont reportés sont très différents d’une étude à l’autre. Les critères de sélection de ces études à savoir : publication dans des revues à comité de lecture, écrites en anglais, réalisée chez des enfants de moins de 18 ans, ont permis d’en recenser seulement neuf ! En outre, la plupart des résultats des études sont basés sur des analyses de corrélations entre l’amélioration des capacités perceptives et/ou linguistiques et la durée de l’entrainement musical (voir par exemple Chen et al., 2010) (Gfeller, 2016). Cependant, nous présenterons ici seulement les résultats de quelques rares études qui incluent un groupe contrôle dans leurs analyses ; en effet, seules ces études nous permettent de conclure précisément sur les effets de transfert d’un entrainement musical sur les capacités linguistiques.
Rochette et collaborateurs (2014) ont testé chez des enfants sourds profonds implantés et appareillés avec des prothèses conventionnelles, les effets d’un entrainement musical hebdomadaire (1 h00 pendant 2,6 ans) sur leurs capacités de perception auditive et compétences cognitives nécessaires à la perception du langage. Les résultats, qui comparaient les performances d’un groupe ayant suivi l’entrainement musical et un groupe sans entrainement musical, montrent que les enfants qui ont suivi l’entrainement musical ont de meilleures performances dans la tâche d’analyse de scènes auditives - qui est une tâche qui mobilise des capacités nécessaires à la discrimination dans le bruit - ainsi que de meilleurs résultats dans la tâche de mémoire auditive et de discrimination phonétique (Rochette, Moussard, & Bigand, 2014).
Fu et collaborateurs (2015) ont également montré que comparé à un groupe d’enfants implantés cochléaires non entrainés, ceux qui suivent un entrainement auditif quotidien (30 minutes par jour pendant 10 semaines) basé sur la reconnaissance de contours mélodiques, ont de meilleures capacités à identifier des contours mélodiques nécessaires à la perception de la prosodie du langage (Fu, Galvin, Wang, & Wu, 2015). Good et collaborateurs (2017) ont quant à eux testé chez 18 enfants implantés cochléaires âgés de 6 à 15 ans, les effets d’un entrainement de piano versus des cours de peinture d’une durée de 6 mois chacun (à raison de 30 minutes par semaine), sur les compétences musicales et linguistiques. Les mesures ont été récoltées à trois temps différents (en pré, milieu et post entrainement/cours). L’évaluation des aptitudes musicales mesurées à l’aide de la Montréal Battery for Evaluation of Amusia portaient sur la capacité à discriminer des contours mélodiques, des intervalles, des échelles, des rythmes ainsi que sur la capacité à mémoriser une mélodie de manière incidente (i.e. analyser dans quelle mesure le sujet, alors qu’il réalise une autre tâche, est capable de mémoriser une mélodie sans que cela lui ait été explicitement demandé). Les aptitudes langagières portaient sur la capacité à reconnaître, suite au visionnage (modalité audio-visuelle) ou à l’écoute seule (modalité auditive pure), des émotions véhiculées par la prosodie avec différents niveaux d’expressivité. Les résultats ont montré que l’entrainement musical, comparé à l’activité peinture, permettait l’amélioration de la discrimination des contours mélodiques, des rythmes, de l’apprentissage incident des mélodies et des scores au test de prosodie émotionnelle des enfants implantés cochléaires (Good et al., 2017).
Pour résumer, il existe peu d'études à notre connaissance qui ont analysé les effets d'une stimulation musicale sur les capacités de production de la parole chez l’enfants sourd. Néanmoins, il semble qu'un entrainement musical non seulement améliore chez les enfants implantés cochléaires, la perception des paramètres acoustiques musicaux tels que la hauteur et les contours mélodiques, éléments présents dans la prosodie du langage, mais que la pratique de la musique engendre également des effets de transfert direct sur les compétences cognitives et linguistiques nécessaire à une bonne perception du langage.
Informations
Ceci c'est une portion transcripte présente sur le PDF en anexe, tous droits sont réservés à l'auteur de la thèse